Cómo optimicé una función central del framework de pruebas del ERP
Cómo optimicé una función central del framework: adapté dos tipos de grilla, corregí un bug lógico y reduje un 33% el tiempo de ejecución.
De qué va este post
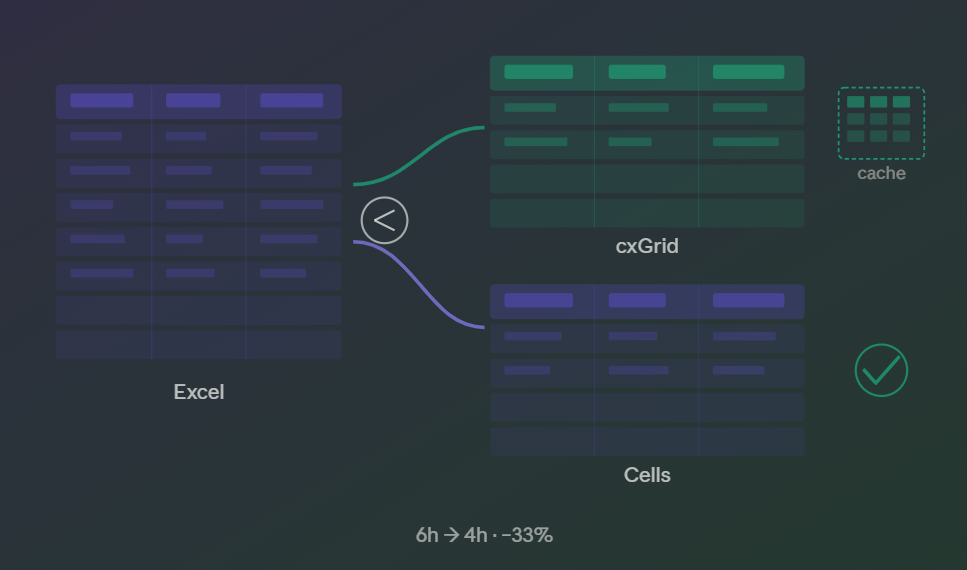
Una función central del framework validaba grillas contra Excel en todo el ERP. Cuando la adapté para soportar dos tipos de grilla (Cells y cxGrid), encontré tres problemas mayores: una búsqueda redundante que hacía más lenta cada corrida, un bug lógico que dejaba pasar filas extra, y casos especiales que exigían variantes separadas.
Resultados
- mejora de ~6h a ~4h en un proyecto crítico
- detección de bugs que antes pasaban desapercibidos
- compatibilidad entre dos tipos de grilla sin romper el framework existente
El contexto: una función que toca todo
En nuestro framework de automatización con TestComplete, existe una función llamada Fn_ValidarGrilla. Su trabajo es simple de describir y complejo de ejecutar: toma una grilla del ERP, la compara celda por celda contra un Excel con valores esperados, y reporta las diferencias.
Suena directo. El problema es que esta función se usa en todas partes. Cada vez que un proyecto automatizado genera una factura, valida un Libro IVA, consulta stock histórico, revisa cuentas corrientes, o verifica cualquier reporte — llama a Fn_ValidarGrilla. Es de las funciones más invocadas del framework.
Cuando una función así tiene problemas de performance o un bug lógico, el impacto no es local. Es sistémico.
Qué valida realmente esta función
Para dimensionar la complejidad, la función no solo comparaba texto plano contra texto plano. Valida:
- Valores numéricos con formato de moneda, porcentajes, cantidades
- Fechas dinámicas calculadas en runtime mediante palabras clave especiales (por ejemplo, "sumar 3 días a la fecha del sistema")
- Colores de fila — validando que la fila tuviera el color visual correcto
- Colores de letra — validando el color de la fuente en filas específicas
- Nombres de columna — incluyendo signos y errores ortográficos del ERP
- Columnas invisibles — que existen internamente en la grilla pero no se muestran en la UI
- Coincidencia de cantidad de registros — que el ERP y el Excel terminen en la misma fila
Todo esto leído desde Excels de validación con múltiples solapas — cada solapa corresponde a una grilla diferente del ERP: consultas de facturas, planilla de caja, ajustes de stock, rentabilidad por comprobante, libro diario, clientes, proveedores, entre otras.
El detonante: grillas que dejaron de funcionar
Hasta la cierta versión del ERP, todas las grillas del sistema eran del mismo tipo. TestComplete las reconocía como componentes de tipo Cells, y se accedía a sus valores con una sintaxis simple:
grilla.ObtenerValor(fila, columna)
↑Pero en una versión nueva, desarrollo migró algunas pantallas a un componente diferente: cxGrid (internamente en QA Automation le quedó el nombre "DBGrid"). La ruta que mostraba el Object Spy de TestComplete cambió, y con ella, la forma de acceder a los datos:
grilla.ObtenerTexto(fila, columna)
↑Dos diferencias críticas: la propiedad de acceso cambió completamente (distinto método, distinta ruta de objeto), y el componente cxGrid no acepta los mismos métodos que Cells — intentar acceder con la sintaxis anterior directamente genera error. Aunque ambos reciben los parámetros en el mismo orden (fila, columna), todo lo demás cambió: el método de acceso, la forma de recorrer columnas, y el comportamiento al intentar leer filas vacías.
No todas las pantallas migraron. Facturación de ventas seguía con Cells. ABM de clientes ya usaba cxGrid. Se nos dijo que la migración era temporal, que eventualmente todo sería cxGrid. Años después, todavía conviven ambos tipos. Ventanas tan importantes como Stock > Histórico de Artículos siguen usando Cells.
La función original solo manejaba Cells. Había que adaptarla para que funcionara con ambos tipos sin romper nada de lo existente.
Restricciones del cambio
Cualquier modificación a una función así tiene un riesgo enorme. Si rompés algo, rompés todo el framework. Las restricciones que me impuse:
- No tocar la interfaz con Excel. La forma en que la función lee datos del Excel debía quedar intacta. Los QAs del equipo armaban sus Excels de validación con una estructura establecida — cambiar eso hubiera requerido rehacer cientos de archivos.
- No romper la validación de nombres de columna. La función verifica que los nombres en el Excel coincidan con los de la grilla. Esa lógica debía seguir funcionando exactamente igual. Hay que validar que ciertas columnas se muestren en la UI, aparezcan y muestren datos.
- Compatibilidad total hacia atrás. Los scripts existentes que usaban el modo Cells debían seguir funcionando sin cambios más allá de agregar el cuarto parámetro.
Primera intervención: bifurcar la función
La solución fue agregar un parámetro tipoGrilla a la firma de la función y crear dos caminos internos con un Select Case:
' Antes: 3 parámetros
Funcion ValidarGrilla(grilla, filaInicio, columnaInicio)
' Después: 4 parámetros
Funcion ValidarGrilla(grilla, filaInicio, columnaInicio, tipoGrilla)
Dentro de la función, cada tipo de grilla tiene su propio bloque de validación:
Segun tipoGrilla:
Caso "cxGrid":
' Acceso vía propiedades internas del componente
' Método, ruta de objeto y comportamiento diferentes
Caso "Cells":
' Acceso vía método cells del componente
' Método original, compatible con grillas anteriores
Fin
Desde cada script del framework, la llamada pasó a incluir el tipo de grilla como último argumento:
Llamar ValidarGrilla(grilla, fila, columna, "Cells")
Este cambio implicó modificar cómo se invocaba la función en todos los proyectos del framework — ventas, compras, stock, fondos, producción, contabilidad. No lo hice solo: una vez que la función estuvo lista y probada, comuniqué al equipo la nueva forma de llamarla, y cada compañero la fue adoptando al estabilizar sus proyectos.
El problema de performance: recalcular lo mismo cientos de veces
Al meterme en el código para hacer la bifurcación, empecé a debuggear a fondo. Y encontré algo que venía costando horas de ejecución sin que nadie lo notara.
El problema
En las grillas cxGrid, para acceder al valor de una celda necesitás saber la posición interna de la columna. Esa posición no coincide necesariamente con el orden visual — la columna "Fecha" puede ser la segunda en pantalla pero la quinta internamente.
La versión original de la función buscaba esta posición en cada fila, para cada columna. Si la grilla tenía 10 columnas y 50 filas, estaba haciendo 500 búsquedas de posición de columna. El 98% era redundante — las posiciones no cambian entre filas.
Donde más se notaba era en el proyecto de validación de Libro IVA de Ventas/Compras, que generaba facturas, notas de crédito y notas de débito, y validaba el Libro IVA después de cada comprobante. Como el Libro IVA es acumulativo, con cada comprobante nuevo la grilla crecía. Las primeras validaciones eran rápidas. Las últimas, con grillas de decenas de filas, eran exponencialmente más lentas.
La solución: caché de posiciones con una matriz
Implementé una matriz que almacena las posiciones internas de las columnas en la primera iteración:
Declarar matrizPosiciones(cantidadColumnas)
Para cada fila de la grilla:
Para cada columna a validar:
' Solo en la primera fila: buscar y cachear posiciones
Si es la primera fila:
nombreExcel = Normalizar(nombreColumnaExcel)
posicion = 0
Mientras Normalizar(grilla.NombreColumna(posicion)) <> nombreExcel:
posicion = posicion + 1
Si posicion > limite: Advertir y salir ' Safety exit
Fin Mientras
matrizPosiciones(columna) = posicion ' Cachear
Fin Si
' Todas las filas: usar posición cacheada directamente
valorGrilla = grilla.ObtenerTexto(fila, matrizPosiciones(columna))
Comparar(valorExcel, valorGrilla)
Siguiente columna
Siguiente fila
La clave: en la primera fila recorre las columnas de la grilla buscando la posición interna de cada columna del Excel. A partir de la segunda fila, accede directamente por posición sin buscar.
El impacto medido
Lo medí con el proyecto que más invoca la función: el de validación de Libro IVA. De todos los proyectos del framework, es el que hace el ciclo de "generar comprobante → validar grilla" más veces, con grillas que crecen progresivamente.
Antes: ~6 horas de ejecución. Después: ~4 horas de ejecución. Mejora: 33%.
Pero la reducción de tiempo no es solo conveniencia. Las corridas se lanzaban con archivos .bat en máquinas dedicadas. Si durante esas 6 horas aparecía un cartel de Windows Update, el ERP crasheaba, o la máquina daba pantallazo azul — perdías las 6 horas completas. Menos tiempo corriendo = menos ventana de exposición a fallos externos.
Nadie me asignó esta optimización. Al entrar al código para la bifurcación de grillas, vi que la lógica interna podía mejorarse, y pasé varios días debuggeando y reescribiendo hasta que funcionó. Cuando comuniqué el resultado a la jefa, la reacción fue tibia — y tiene sentido. Ella no solo lideraba al equipo de QA Automation: también lideraba al equipo de testers manuales que atiende a las empresas beta testers — compañías que usan el software de forma gratuita a cambio de probar versiones recién salidas de desarrollo, versiones que suelen tener bugs. Cuando una empresa beta tester llama con un problema urgente, hay que atenderla. Estábamos en medio de ciclos de versión intensos, con incendios en QA Automation, incendios en beta testing, y la jefa ayudando para apagar ambos. La mejora quedó como un "bien, bien" sin celebración particular.
A veces las mejoras de infraestructura no generan aplausos porque el equipo está apagando incendios en todos los frentes. Es exactamente el tipo de trabajo invisible que un QA hace y que nadie celebra pero todos usan.
Antes / Después
- Antes: búsqueda de posición de columnas en cada fila
- Después: caché de posiciones en la primera iteración
- Impacto: de ~6h a ~4h en Libro IVA
- Mejora: 33% menos tiempo de ejecución
El bug lógico: filas fantasma
Además del problema de performance, encontré un defecto en la lógica de validación.
El escenario
Supongamos que el Excel de validación tiene 5 filas de datos esperados, y la grilla del ERP muestra 7 filas. La versión original iteraba sobre las 5 filas del Excel, las encontraba en la grilla, y reportaba: todo OK.
Pero no lo estaba. Había 2 filas en el ERP que no tenían correspondencia en el Excel. Podían ser registros duplicados, comprobantes fantasma, errores de cálculo — bugs reales que pasaban desapercibidos porque la función nunca verificaba que ambas fuentes terminaran en la misma fila.
Peor que un test que falla es un test que dice “todo OK” cuando dejó pruebas/datos sin validar.
La solución
Agregué una validación de última fila: cuando la función llega al final de los datos del Excel, compara contra la última fila real de la grilla del ERP:
' Al llegar a la última fila del Excel:
Si estamos en la última fila esperada:
Registrar "--- Comparación: Última fila Excel vs Última fila Grilla ---"
ultimaFilaGrilla = grilla.CantidadFilas - 1
Para cada columna:
Comparar(valorExcel, grilla.ObtenerTexto(ultimaFilaGrilla, posicionColumna))
Siguiente
Fin
Si la última fila del Excel no coincide con la última fila de la grilla, la función reporta la diferencia. Esto empezó a detectar bugs que antes pasaban como si no existieran.
El detalle sutil: normalización de nombres de columna
Un problema recurrente al comparar nombres de columna entre el Excel y la grilla era que fallaban por diferencias de formato, no de contenido. La grilla del ERP podía mostrar "Código" y el Excel decir "Codigo" (sin tilde). O la grilla tenía un espacio extra, o un punto de más, o un signo especial como "°" o "%" que en el Excel estaba escrito ligeramente diferente.
Creé una función de normalización que limpia ambos valores antes de compararlos:
Funcion Normalizar(cadena):
' 1. Reemplazar caracteres con tilde por equivalentes sin tilde
' á→a, é→e, í→i, ó→o, ú→u (y mayúsculas)
' 2. Eliminar caracteres de formato
' Espacios, puntos, signos de interrogación, paréntesis,
' guiones, barras, porcentajes, grados
' 3. Convertir todo a mayúsculas
Retornar cadenaNormalizada
Fin Funcion
' Ejemplo: "Código" y "Codigo" → ambos se convierten en "CODIGO"
' Ejemplo: "% Bon." y "%Bon" → ambos se convierten en "BON"
Con esto, "Código" y "Codigo" se convierten ambos en "CODIGO" antes de compararse. La función valida correctamente sin generar falsos negativos por problemas de formato.
Lo que parece un detalle menor eliminó una categoría entera de fallos espurios que hacían perder tiempo al equipo investigando "errores" que no eran errores del ERP.
Las grillas que se resistieron: funciones hermanas
Con los cambios realizados, Fn_ValidarGrilla funcionaba correctamente para la gran mayoría de las ventanas del ERP. Pero algunas grillas se resistieron.
Libro Diario
La ventana de Contabilidad > Libro Diario tiene una estructura completamente diferente. Los asientos contables actúan como headers dentro de la grilla ("Asiento Nº 9", "Asiento Nº 10"), con filas de detalle debajo (cuentas contables con Debe/Haber), líneas de observaciones, y filas vacías como separadores entre asientos.
La función principal calcula automáticamente cuántas filas validar — se detiene cuando encuentra una fila vacía. En Libro Diario, las filas vacías son parte normal de la estructura. La función original se frenaba prematuramente.
Pero el problema iba más allá de que se frenara. Esas filas vacías no son ruido — son datos esperados que deben validarse. El Excel de validación incluye esas filas vacías explícitamente, y la función debe confirmar que el ERP efectivamente muestra vacío donde debe mostrar vacío. Si un asiento contable deja de mostrar su separador, eso es un defecto visual que hay que reportar.
Esto cambió la función de comparación. La función principal usa una rutina de comparación que descarta vacíos como "no hay dato". Las variantes hermanas usan una rutina de comparación diferente, que acepta vacíos como valor válido. Un vacío en el Excel comparado contra un vacío en la grilla es un resultado correcto — no algo que ignorar.
Además, el componente exponía los nombres de columna mediante una propiedad diferente a la habitual, y los datos venían con caracteres de tabulación que la función de limpieza estándar de VBScript no eliminaba (requirió crear una función de limpieza extendida).
La solución: crear una función hermana específica para Libro Diario, con un parámetro adicional filaHasta que define explícitamente el rango de validación, en vez de calcularlo automáticamente.
Análisis Avanzado
La ventana de Informes > Análisis Avanzado presentó un desafío técnico que no tenía precedente en el framework.
En todas las grillas anteriores — tanto Cells como cxGrid — TestComplete podía acceder a los valores internamente aunque no estuvieran visibles en pantalla. La grilla podía tener scroll horizontal y vertical con datos "escondidos" en la UI, pero TC los leía sin problemas a través de las propiedades del objeto.
En Análisis Avanzado, eso dejó de funcionar. No había panel ni método que expusiera los valores no visibles. El Object Spy no mostraba propiedades útiles para datos fuera del viewport.
La solución fue simular navegación real por la grilla — literalmente recorrerla como lo haría un usuario:
' Contar cuántas filas caben visibles en pantalla
filasVisibles = grilla.ObtenerCantidadFilasVisibles()
' Posicionar el foco en la primera fila
grilla.EnfocarFila(0)
Para cada fila:
Para cada columna:
' Simular tecla derecha para revelar la columna en pantalla
grilla.Tecla("[Derecha]")
' Leer el valor que el componente está "pintando" en ese momento
Si fila >= filasVisibles:
valor = grilla.TextoVisibleEn(filasVisibles - 1, posicionColumna)
Sino:
valor = grilla.TextoVisibleEn(fila, posicionColumna)
Fin Si
Comparar(valorExcel, valor)
Siguiente columna
' Bajar una fila y volver al inicio horizontal
grilla.Tecla("[Abajo]")
Repetir cantidadColumnas veces: grilla.Tecla("[Izquierda]")
Siguiente fila
La única propiedad que devolvía los valores era una que expone literalmente el texto que el componente está pintando en la pantalla en ese momento. No es un método de acceso a datos — es un método de renderizado. Para que funcionara, había que navegar la grilla para que cada valor estuviera visible al momento de leerlo.
No es elegante. Funciona. Cuando la herramienta no da acceso directo a los datos, encontrás caminos alternativos o no testeás.
Al igual que Libro Diario, Análisis Avanzado también tiene filas vacías como parte de su estructura (separadores entre grupos de rubros y totales), por lo que esta variante también usa la rutina de comparación que acepta vacíos como dato esperado.
Quise hacer una sola función universal para todo, pero las ventanas que necesitaban estos cambios eran tan pocas que no justificaba complejizar la función principal. Mantener funciones hermanas separadas fue la decisión de ingeniería correcta: cada variante resuelve un caso específico sin agregar complejidad a los demás.
Conclusiones técnicas
Una función central optimizada mejora todo el framework de golpe. No necesitás reescribir 50 proyectos — arreglá la función que todos llaman y los 50 mejoran automáticamente.
Los bugs lógicos en infraestructura son los más peligrosos. El defecto de no validar la última fila no generaba errores visibles — generaba falsos positivos silenciosos. La función decía "todo OK" cuando había registros sin verificar. Este tipo de defecto es peor que uno ruidoso, porque te da confianza falsa.
Las migraciones "temporales" se vuelven permanentes. La convivencia Cells/cxGrid iba a ser transitoria. Años después, sigue vigente. Diseñar para ambos casos desde el principio fue la decisión correcta.
Pragmatismo sobre purismo. Una función universal para todas las variantes hubiera sido más elegante. Funciones hermanas para los 2-3 casos atípicos es más mantenible. El código perfecto que nunca se termina no optimiza nada.
Las mejoras de infraestructura no generan aplausos. Y no importa. Lo que importa es que cuando el equipo corre una validación, la función funciona, es rápida, detecta lo que tiene que detectar, y no genera falsos negativos que desperdicien tiempo.
Cierre
Las funciones más peligrosas de un framework no siempre son las más complejas, sino las más invocadas. Cuando una función central es lenta o tiene un bug lógico, el problema no queda encerrado en un proyecto: se propaga por todo el sistema de pruebas.
Optimizar Fn_ValidarGrilla no fue “mejorar una función”. Fue mejorar un punto de apoyo del framework entero.
Si mantenés un framework de automatización, empezá por ahí: no por lo más vistoso, sino por lo que más veces corre.
Relacionado:
QA en ERP complejos: cómo reporté el 37% de los bugs de mi equipo en 4 años
El marco más amplio detrás de este tipo de trabajo: priorización por riesgo, edge cases, mejoras de infraestructura y decisiones que aumentan el impacto real del QA.
