Page Object Model en Playwright: 3 pages, 2 errores y la diferencia con Selenium
3 page objects, 2 errores reales (baseURL, exact match), refactor completo. Lo que Playwright resuelve solo vs lo que en Selenium armé a mano.
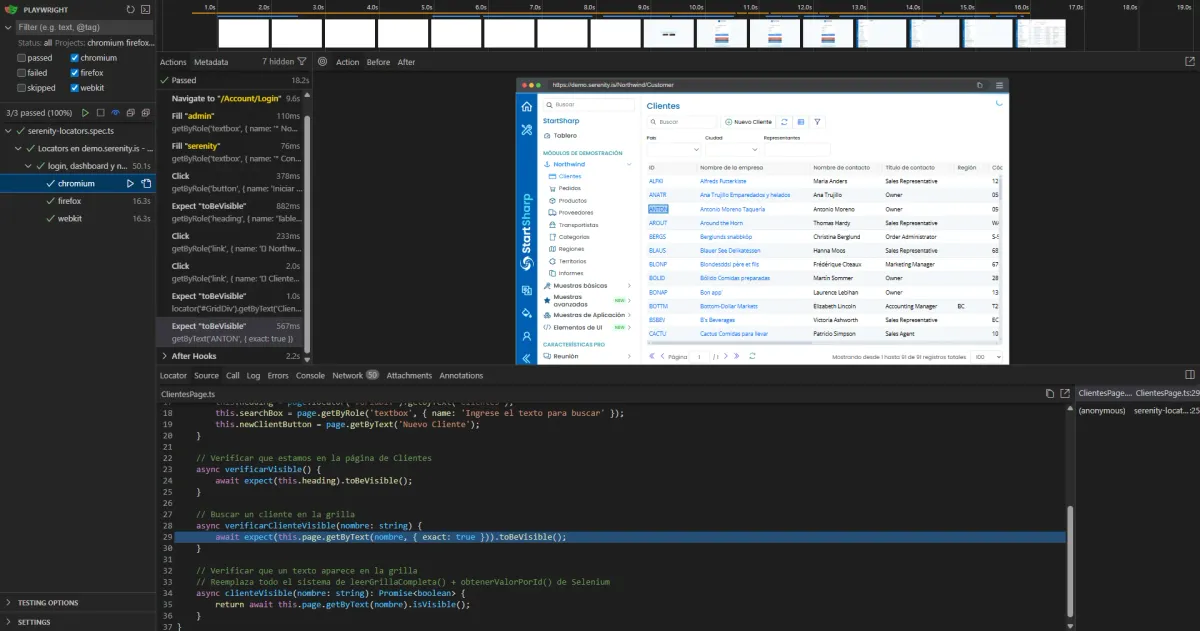
El problema
Mirá cómo quedó el test del Post anterior:
Todo en un solo bloque. Locators sueltos, login hardcodeado, sin estructura. Si mañana agrego 10 tests más, repito el login 10 veces. Si cambia el botón de login, lo corrijo en 10 lugares.
Page Object Model resuelve esto: cada página de la app se convierte en una clase. Los locators quedan en la clase. Los tests usan métodos, no locators.
Ya hice esto en Selenium. Mi LoginPage.java tiene los locators del login, mi DashboardPage.java tiene los del dashboard, mi ClientesPage.java tiene los de la grilla. Ahora hago lo mismo en Playwright, contra la misma app, y veo qué cambia.
Estructura: dónde va pages/
Creé la carpeta pages/ en la raíz del proyecto, al mismo nivel que tests/:
playwright-typescript-framework/
├── pages/ ← nueva
│ ├── LoginPage.ts
│ ├── DashboardPage.ts
│ └── ClientesPage.ts
├── tests/
│ ├── example.spec.ts
│ ├── saucedemo.spec.ts
│ └── serenity-locators.spec.ts
├── playwright.config.ts
└── package.json
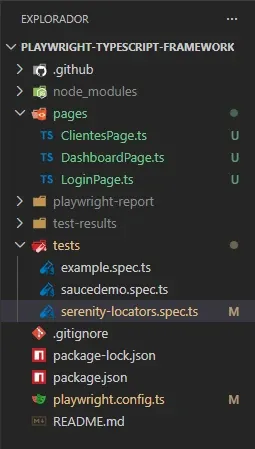
Misma lógica que en Selenium donde pages/ está en src/main/java y los tests en src/test/java. Pages y tests separados.
El flujo: codegen → locators → page class
Para cada page, el proceso fue el mismo:
- Abrir codegen:
npx playwright codegen demo.serenity.is - Interactuar con la app (login, navegar, clickear)
- Copiar los locators que codegen genera
- Separarlos en la page class: locators en el constructor, acciones en métodos
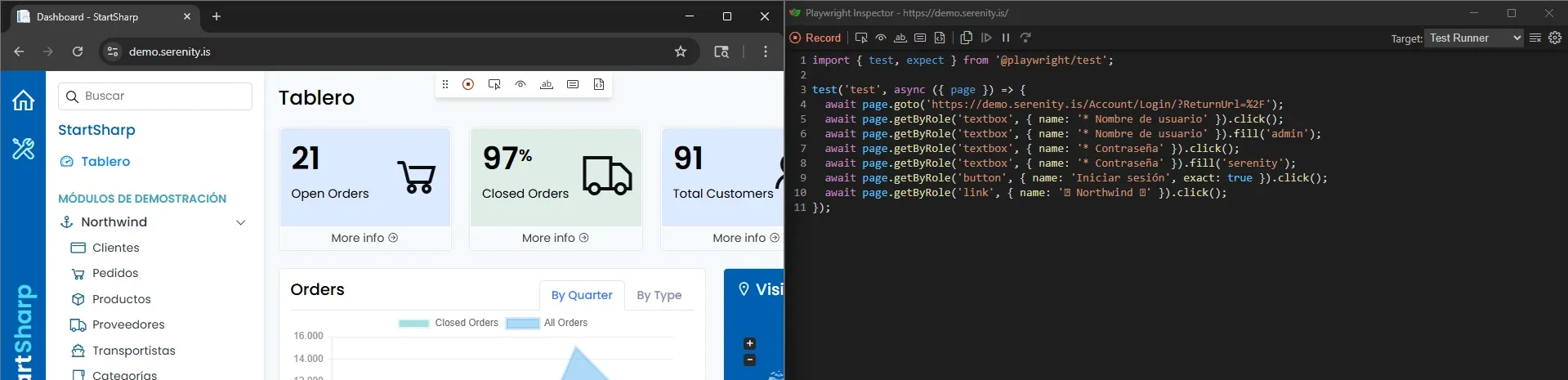
Codegen genera todo junto:
await page.getByRole('textbox', { name: '* Nombre de usuario' }).click();
await page.getByRole('textbox', { name: '* Contraseña' }).click();
await page.getByRole('button', { name: 'Iniciar sesión', exact: true }).click();
Yo lo separo: locators al constructor, acciones a métodos.
En Selenium no tenía esto. Abría DevTools, inspeccionaba el HTML, armaba el XPath o CSS selector a mano. Acá codegen me da el locator directo.
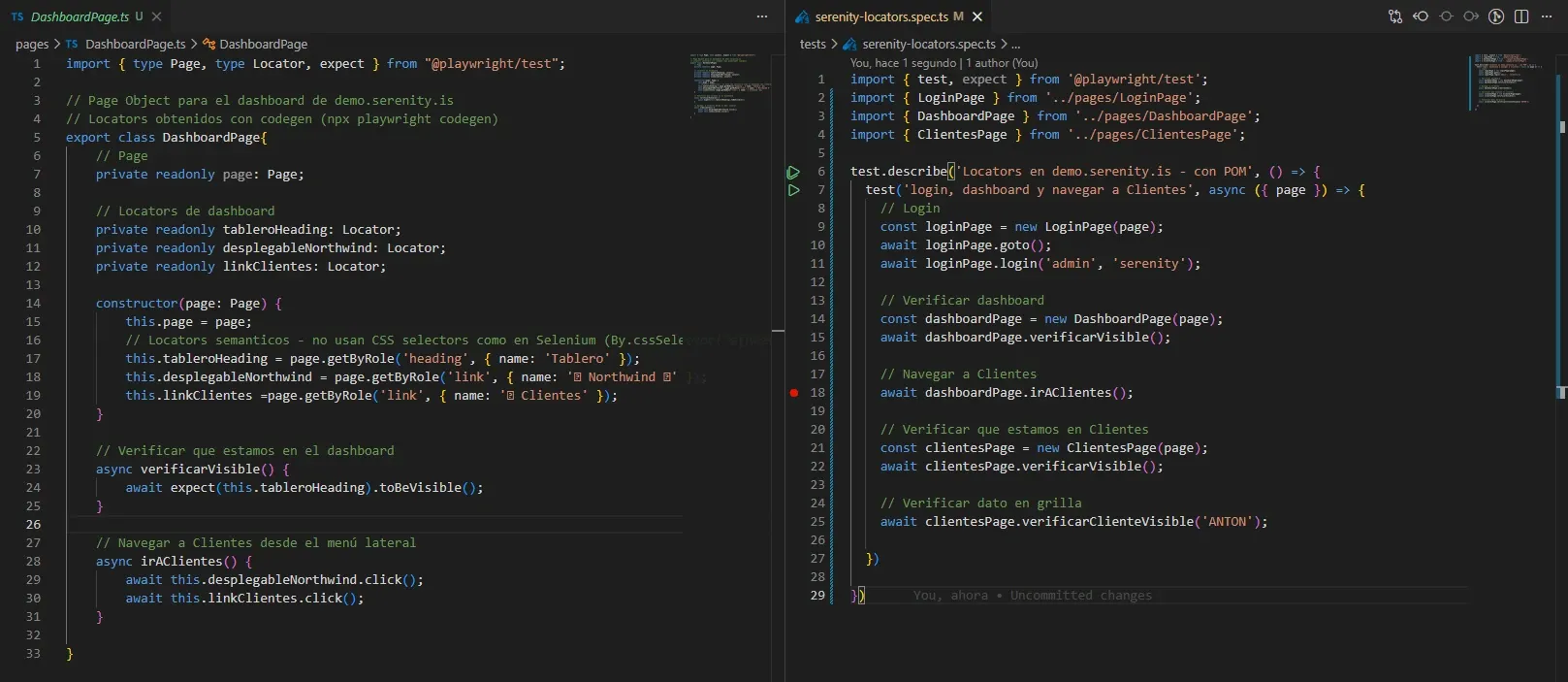
Las 3 pages
LoginPage.ts
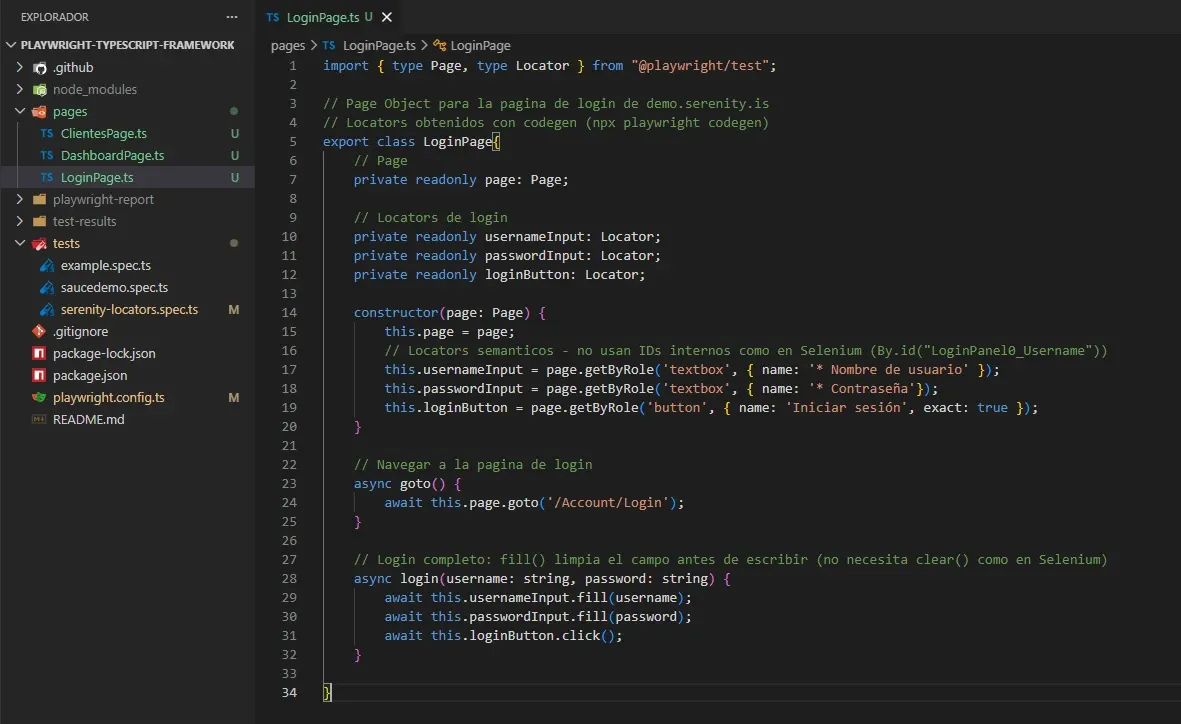
Comparalo con mi LoginPage.java de Selenium:
// Selenium: locators con IDs internos del HTML
private final By usernameInput = By.id("LoginPanel0_Username");
private final By passwordInput = By.id("LoginPanel0_Password");
private final By loginButton = By.id("LoginPanel0_LoginButton");
// Selenium: cada acción necesita espera explícita + clear()
public void enterUsername(String username) {
WebElement usuarioInputElement = wait.until(ExpectedConditions.visibilityOfElementLocated(usernameInput));
usuarioInputElement.clear();
usuarioInputElement.sendKeys(username);
}
Diferencias:
- Locators: Selenium usa
By.id("LoginPanel0_Username")(ID interno del HTML). Playwright usagetByRole('textbox', { name: '* Nombre de usuario' })(lo que el usuario ve). - Esperas: Selenium necesita
wait.until(ExpectedConditions.visibilityOf...)antes de cada interacción. Playwright auto-espera. - Clear: Selenium necesita
element.clear()antes desendKeys(). En Playwright,fill()limpia solo. - Métodos separados vs uno solo: En Selenium tenía
enterUsername(),enterPassword(),clickLogin()separados. En Playwright un solologin()es suficiente porque no necesito wrappers de espera.
DashboardPage.ts
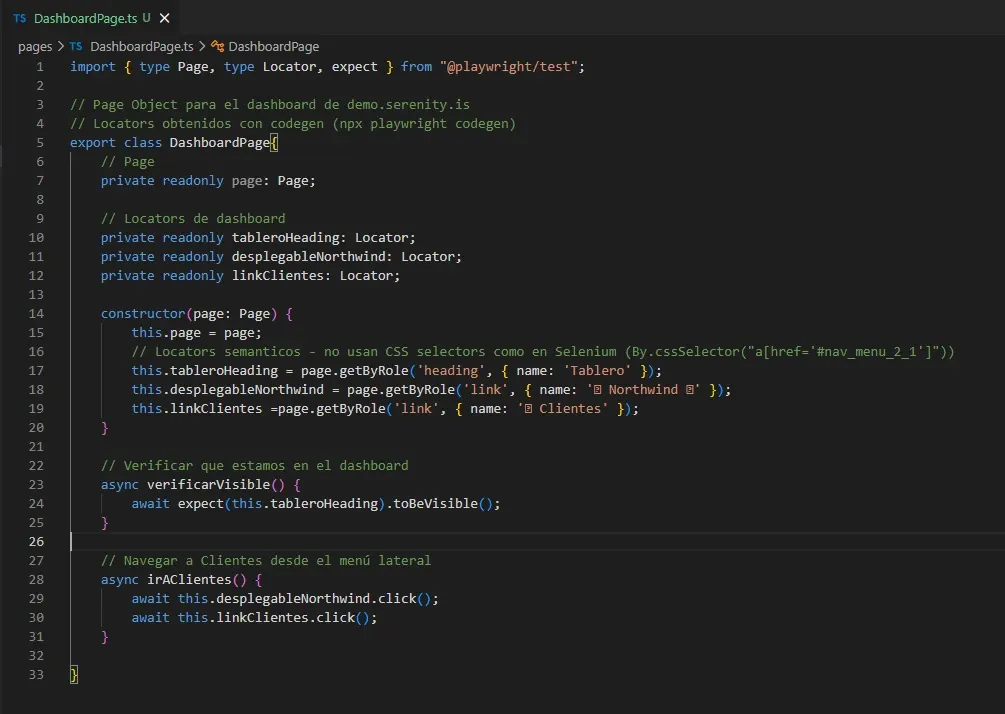
En Selenium mi DashboardPage.java tenía esto para navegar:
public void irAClientes() {
wait.until(ExpectedConditions.elementToBeClickable(btnNorthwind)).click();
wait.until(ExpectedConditions.elementToBeClickable(linkClientes)).click();
}
Dos líneas de wait.until(ExpectedConditions.elementToBeClickable(...)). En Playwright, dos líneas de .click(). El auto-waiting resuelve lo que en Selenium armé a mano.
ClientesPage.ts
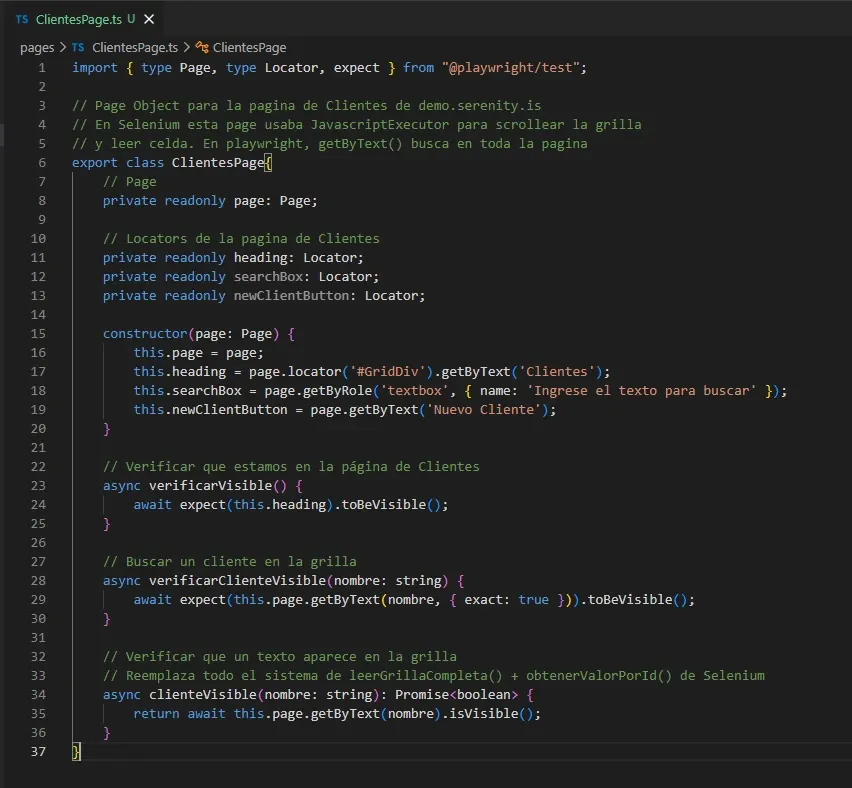
Esta es la diferencia más grande con Selenium.
Mi ClientesPage.java tiene 100+ líneas: JavascriptExecutor para scrollear la grilla, Thread.sleep(200) entre scrolls, un HashMap<String, String[]> para guardar datos en memoria, constantes para cada columna (COL_ID = 0, COL_EMPRESA = 1, etc.).
En Playwright, verificarClienteVisible('ANTON') busca el texto directo. No necesita scroll, no necesita leer celda por celda, no necesita HashMap.
100+ líneas en Selenium → 30 líneas en Playwright. No porque Playwright sea "mejor", sino porque resuelve a nivel de framework lo que en Selenium tenía que resolver yo con código.
El refactor del test
Antes (Post 2): todo inline
test('test', async ({ page }) => {
await page.goto('https://demo.serenity.is/Account/Login');
await page.getByRole('textbox', { name: '* Nombre de usuario' }).fill('admin');
await page.getByRole('textbox', { name: '* Contraseña' }).fill('serenity');
await page.getByRole('button', { name: 'Iniciar sesión', exact: true }).click();
await expect(page.getByRole('heading', { name: 'Tablero' })).toBeVisible();
await page.getByRole('link', { name: '📁 Northwind 📁' }).click();
await page.getByRole('link', { name: '📁 Clientes' }).click();
await expect(page.locator('section')).toBeVisible();
await expect(page.locator('#GridDiv')).toContainText('ANTON');
});
Locators por todos lados. Si cambia algo en el login, tengo que buscarlo acá.
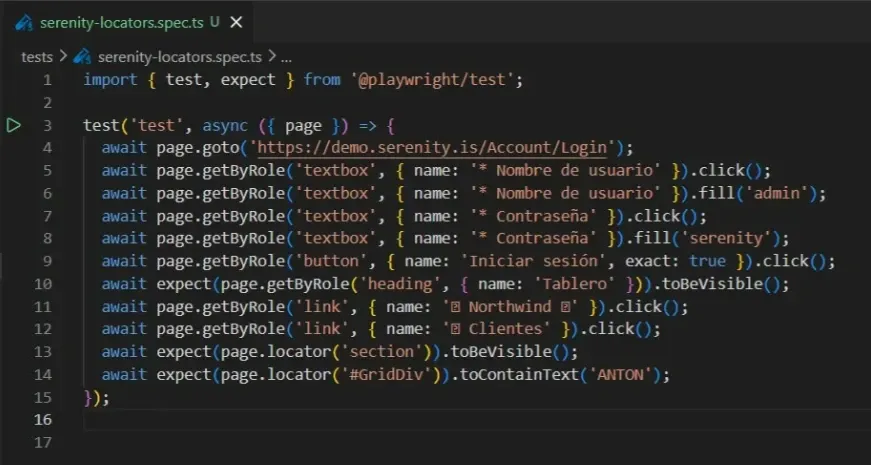
Después (Post actual): con POM
import { test, expect } from '@playwright/test';
import { LoginPage } from '../pages/LoginPage';
import { DashboardPage } from '../pages/DashboardPage';
import { ClientesPage } from '../pages/ClientesPage';
test.describe('Locators en demo.serenity.is — con POM', () => {
test('login, dashboard y navegar a Clientes', async ({ page }) => {
// Login
const loginPage = new LoginPage(page);
await loginPage.goto();
await loginPage.login('admin', 'serenity');
// Verificar dashboard
const dashboardPage = new DashboardPage(page);
await dashboardPage.verificarVisible();
// Navegar a Clientes
await dashboardPage.irAClientes();
// Verificar que estamos en Clientes
const clientesPage = new ClientesPage(page);
await clientesPage.verificarVisible();
// Verificar dato en grilla
await clientesPage.verificarClienteVisible('ANTON');
});
});
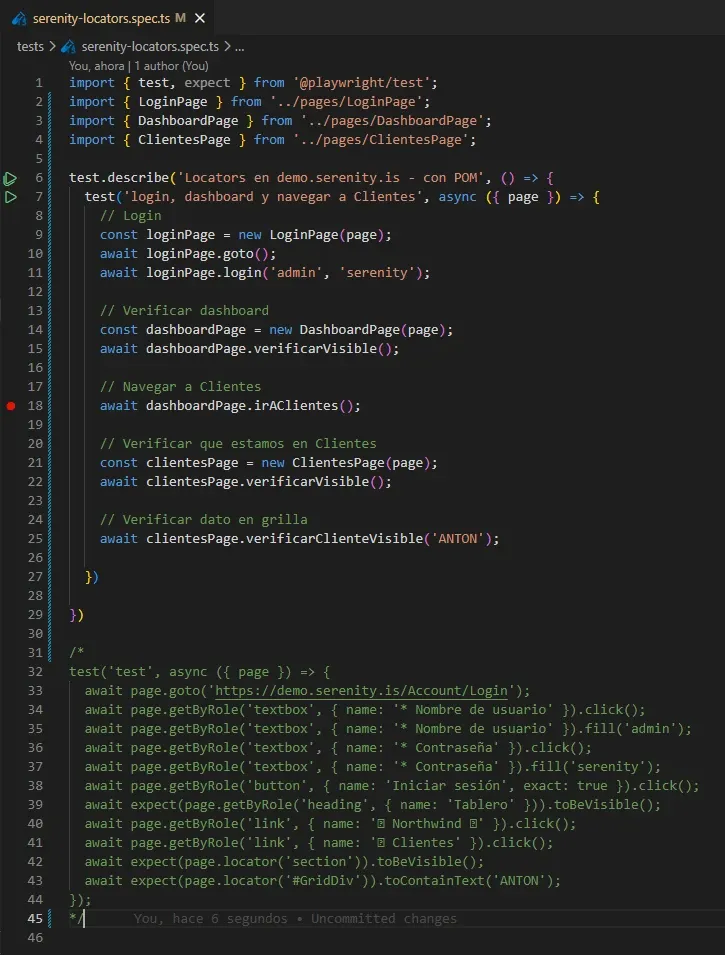
Cero locators en el test. Solo métodos. El test describe qué se hace, las pages resuelven cómo.
Si mañana cambia el botón de login, lo corrijo en LoginPage.ts. Los tests no se tocan.
Dos errores reales
Error 1: baseURL faltante
Primer run después del refactor: el test abrió about:blank.
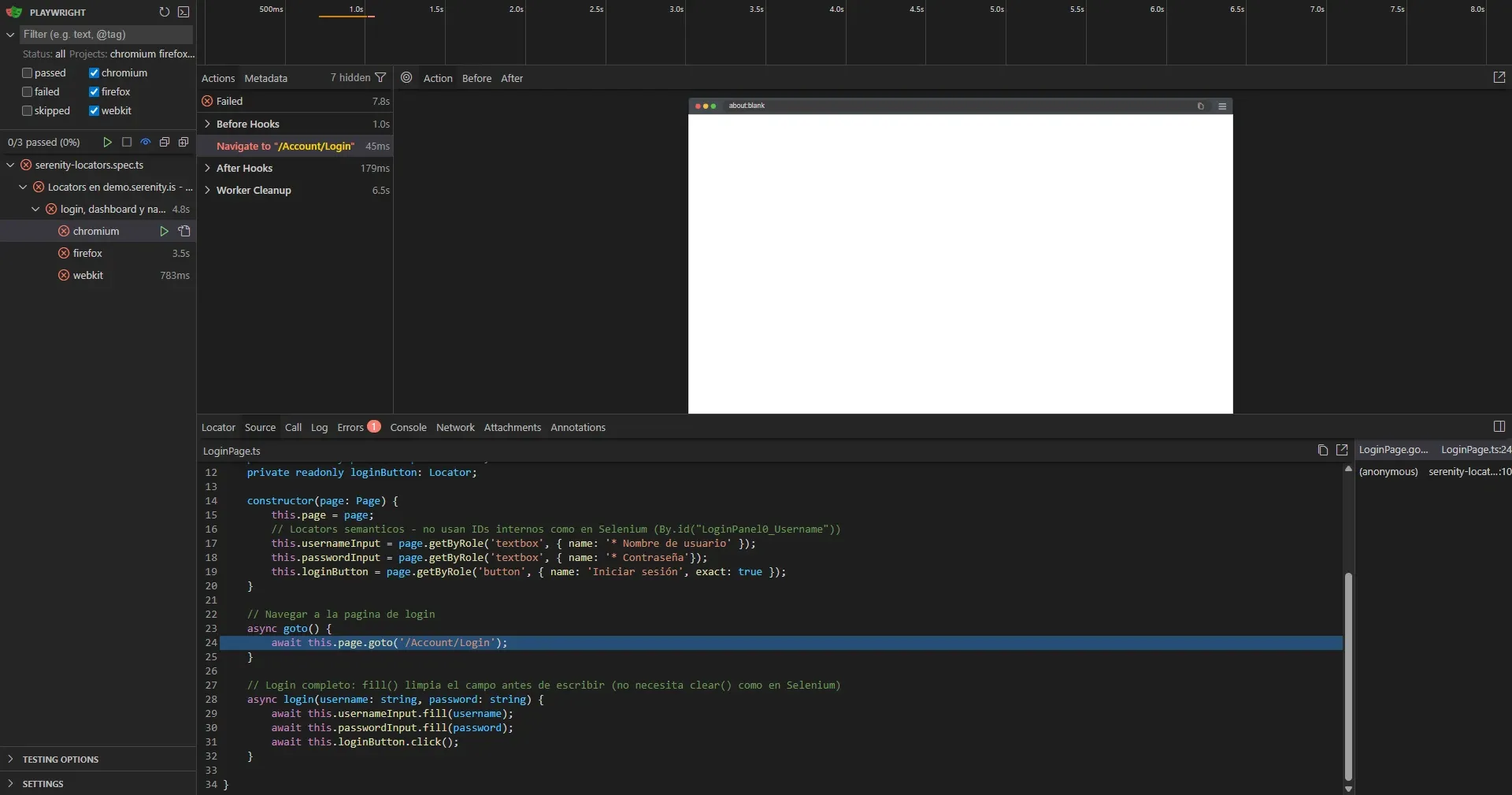
El problema: LoginPage.goto() usa this.page.goto('/Account/Login') — ruta relativa. Pero Playwright no sabía a qué dominio ir porque no tenía baseURL configurado.
La solución: agregar baseURL en playwright.config.ts:
use: {
baseURL: 'https://demo.serenity.is',
},
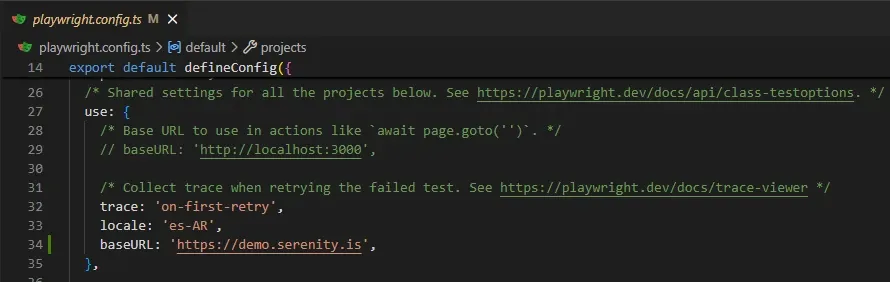
Con eso, goto('/Account/Login') se resuelve a https://demo.serenity.is/Account/Login.
En Selenium resolvía esto con config.properties:
base.url=https://demo.serenity.is
Mismo concepto, distinto lugar. En Playwright todo se centraliza en playwright.config.ts.
Error 2: getByText sin exact match
Segundo run: llegó hasta Clientes (veía la grilla, veía ANTON resaltado en la tabla), pero el test falló.
El problema: getByText('ANTON') hace match parcial. Encuentra "ANTON", pero también "Antonio Moreno" y "Antonio Moreno Taquería". Múltiples coincidencias = Playwright no sabe cuál elegir.
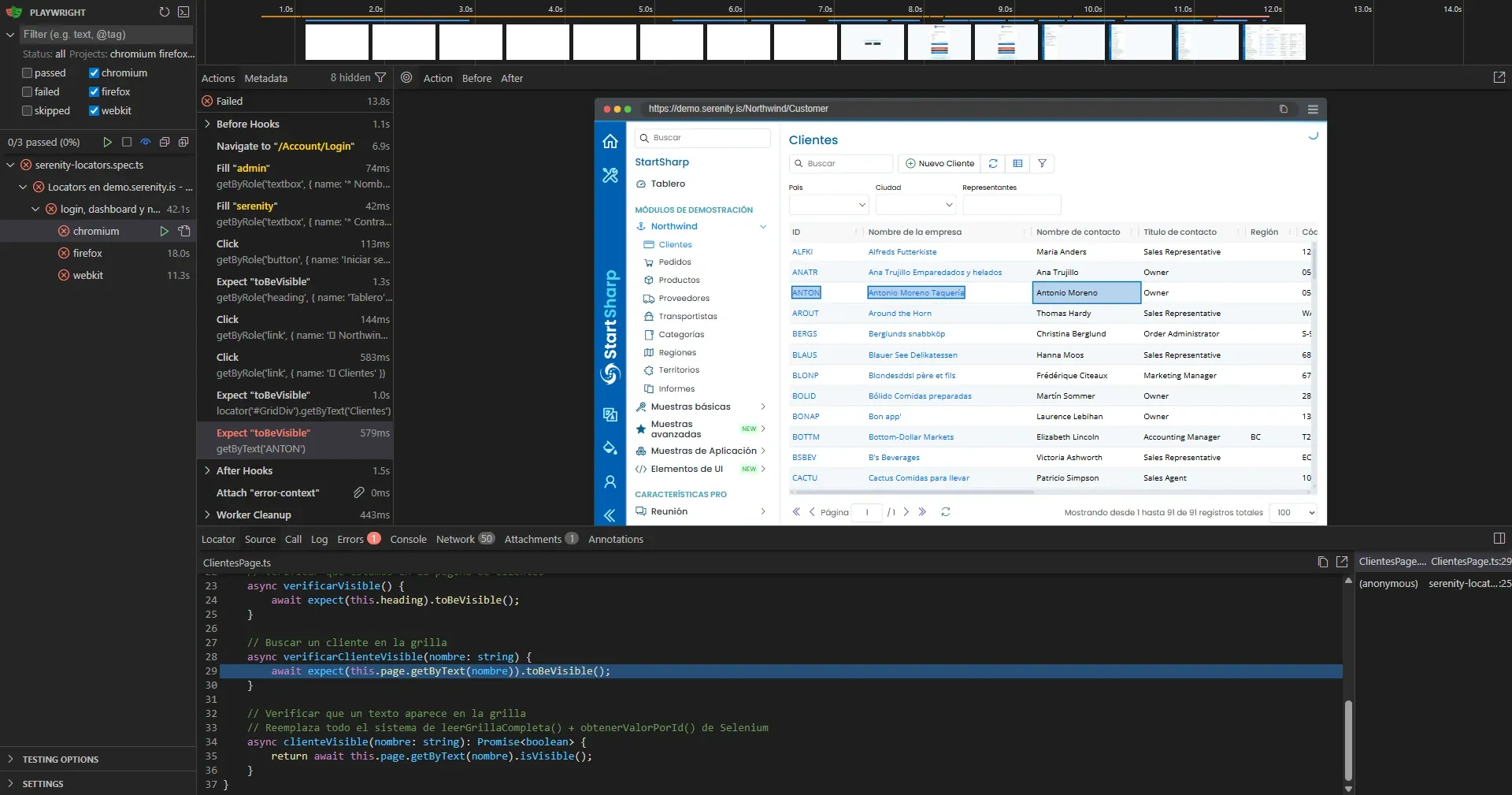
La solución: { exact: true }:
await expect(this.page.getByText(nombre, { exact: true })).toBeVisible();
Este es un error que en Selenium no existía de la misma forma. Con By.cssSelector o By.xpath siempre apuntás a un elemento específico. Con los locators semánticos de Playwright, el match parcial es el default, y hay que ser explícito cuando querés match exacto.
Resultado final
Después de corregir los dos errores:
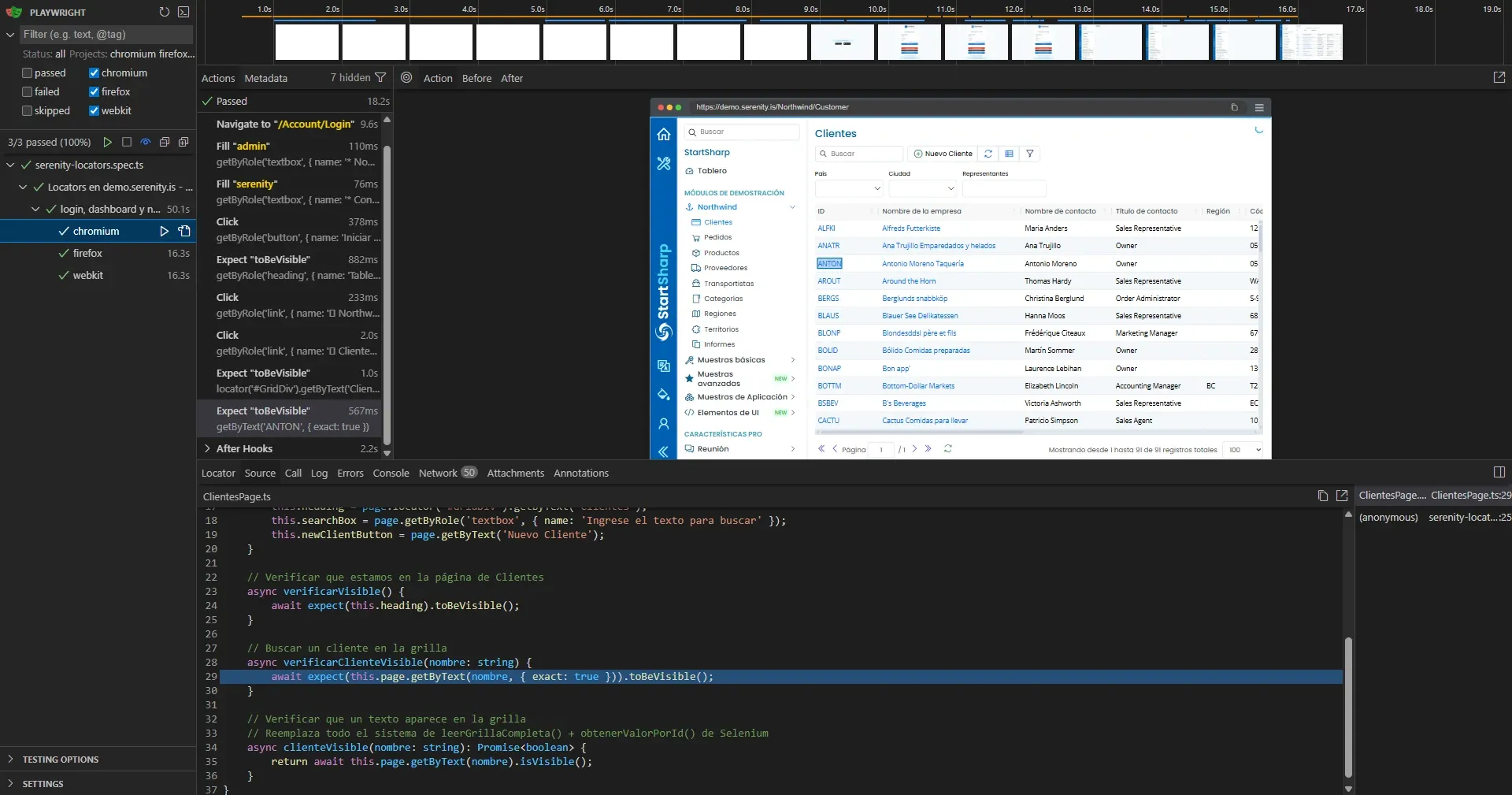
3/3 passed. Los 3 browsers. POM funcionando.
Comparación completa: POM en Selenium vs Playwright
Lo que Playwright no necesita:
| Selenium | Playwright | Por qué no hace falta |
|---|---|---|
BasePage.java |
No existe | Auto-waiting integrado, no necesitás wrappers |
DriverManager.java |
No existe | Playwright maneja el browser con fixtures |
BaseTest.java |
No existe | test.beforeEach reemplaza el setup |
ConfigReader.java |
No existe | playwright.config.ts centraliza todo |
AllureListener.java |
No existe | Reporter se configura en el config |
AllureScreenshot.java |
No existe | Screenshots automáticos en failure |
En Selenium armé 6 clases de infraestructura antes de escribir un test. En Playwright, la infraestructura ya existe. Solo creo pages/ y tests/.
Lo que sí se mantiene igual: el concepto. Una clase por página, locators encapsulados, métodos que representan acciones del usuario. POM es POM en cualquier framework.
Estado actual del proyecto
playwright-typescript-framework/
├── pages/
│ ├── LoginPage.ts
│ ├── DashboardPage.ts
│ └── ClientesPage.ts
├── tests/
│ ├── example.spec.ts
│ ├── saucedemo.spec.ts
│ └── serenity-locators.spec.ts ← refactorizado con POM
├── playwright.config.ts ← baseURL configurado
└── package.json
Tengo:
- 3 page objects funcionando
- Test refactorizado sin locators inline
baseURLcentralizado en el config- 3/3 browsers pasando
Próximo paso: Assertions — web-first assertions, auto-retry, soft assertions. Cómo Playwright maneja las verificaciones vs los Assert.assertEquals de TestNG.
—
🔗 Todo el código de esta serie está en: github.com/cesarbeassuarez/playwright-typescript-framework