Data-driven testing con Newman: CRUD completo alimentado por CSV
Postman cobra por data files en el Runner. Newman lo hace gratis. CSV con 6 escenarios, CRUD parametrizado, assertions condicionales y reportes HTML.
Nota para el lector
El schema validaba la estructura. Ahora los datos vienen de un archivo externo y el CRUD se adapta a cada caso. Cuando el Create falla, el resto se salta solo.
Este post es parte de la serie de API Testing con Postman sobre Serenity Demo (https://demo.serenity.is/Account/Login/?ReturnUrl=%2F). Los posts anteriores cubren el análisis con DevTools, la construcción de requests, el manejo del CSRF token, assertions con pm.test, testing negativo del login, el debugging del Runner, CRUD completo, y schema validation con Ajv.
Contexto
Hasta ahora, todos los datos del CRUD estaban hardcodeados. El Create siempre mandaba "CESBS", "CesarBeasSuarez Industries", "Cesar Beas Suarez". Retrieve, Update, Delete — todo apuntaba a "CESBS". Si quería probar con otros datos, tenía que cambiar el body a mano, correr, cambiar de nuevo, correr de nuevo. Eso no escala.
Quería probar con datos distintos en cada corrida: clientes válidos, campos vacíos, IDs duplicados, datos que la API debería rechazar. Y quería que todo corriera automático, sin tocar Postman.
La solución en API testing profesional es data-driven testing: un archivo externo (CSV o JSON) alimenta las requests, y la herramienta corre una iteración por cada fila.
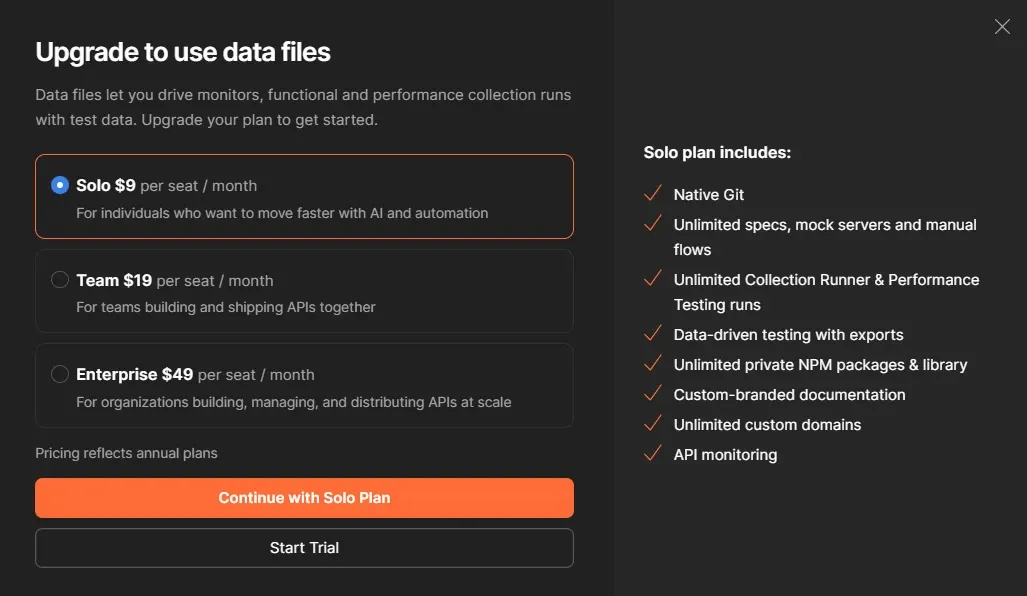
El paywall del Runner
Postman tiene una feature para esto: "Test data file" en el Runner. Le pasás un CSV y corre las iteraciones.
Cuando intenté usarla: paywall. "Upgrade to use data files." Plan Solo, $9/mes.
No iba a pagar $9/mes por algo que puedo hacer gratis.
Newman
Newman es el CLI de Postman. Corre colecciones desde la terminal. Y acepta data files sin restricciones.
¿Qué hace Newman que Postman Runner no (en plan gratuito)?
- Correr colecciones con archivos de datos (CSV, JSON)
- Generar reportes HTML
- Integrarse con CI/CD (GitHub Actions, Jenkins)
- Correr sin interfaz gráfica
Lo que NO hace: editar requests o scripts. Para eso seguís usando Postman.
Newman es la herramienta que lleva Postman a la terminal. Postman para diseñar, Newman para ejecutar.
Instalación
Newman necesita Node.js. No lo tenía instalado.
Node.js
Fui a https://nodejs.org, descargué la versión LTS (v24.14.0), instalé con las opciones por defecto. En la pantalla de "Tools for Native Modules" no tildé nada — Newman no lo necesita.
Cerré PowerShell, abrí de nuevo:
PS> node -v
v24.14.0
PS> npm -v
11.9.0
Newman
PS> npm install -g newman
added 148 packages in 51s
PS> newman -v
6.2.2
Reporter HTML
Newman por defecto muestra resultados en consola. Para tener un reporte visual (parecido a Allure), instalé el reporter htmlextra:
PS> npm install -g newman-reporter-htmlextra
added 194 packages in 41s
Tres herramientas instaladas en 5 minutos: Node, Newman, reporter.
Parametrizar el body del Create
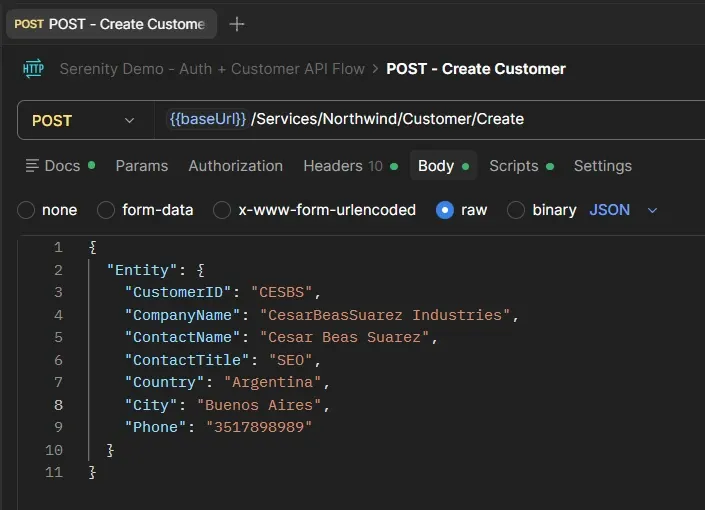
El body del Create Customer estaba así:
{
"Entity": {
"CustomerID": "CESBS",
"CompanyName": "CesarBeasSuarez Industries",
"ContactName": "Cesar Beas Suarez",
"ContactTitle": "SEO",
"Country": "Argentina",
"City": "Buenos Aires",
"Phone": "3517898989"
}
}
Todo hardcodeado. Lo cambié a variables:
{
"Entity": {
"CustomerID": "{{CustomerID}}",
"CompanyName": "{{CompanyName}}",
"ContactName": "{{ContactName}}",
"ContactTitle": "{{ContactTitle}}",
"Country": "{{Country}}",
"City": "{{City}}",
"Phone": "{{Phone}}"
}
}
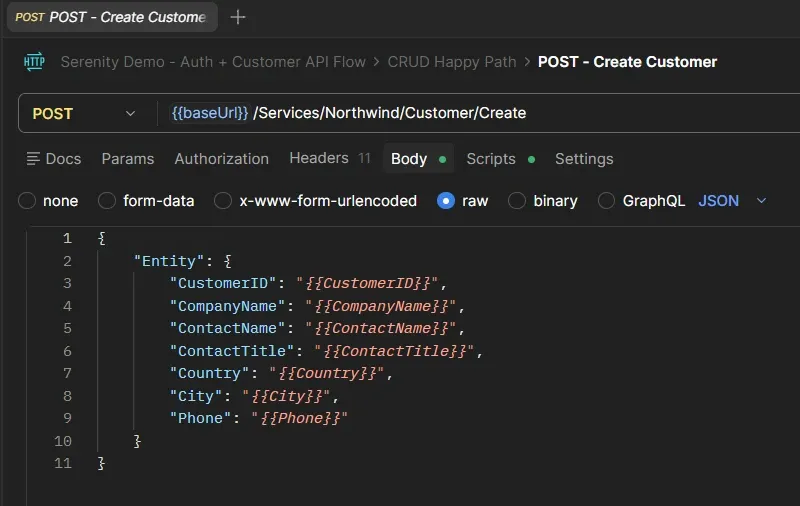
{{CustomerID}}, {{CompanyName}}, etc.) que el CSV reemplaza en cada iteración del Runner.Las {{variables}} se reemplazan automáticamente por los valores del CSV. Newman lo hace en cada iteración.
El CSV
Antes de armar el archivo, necesitaba saber cómo reacciona la API a datos inválidos. Hice tres pruebas manuales.
Sin CompanyName: 400 + "Company Name field is required!"
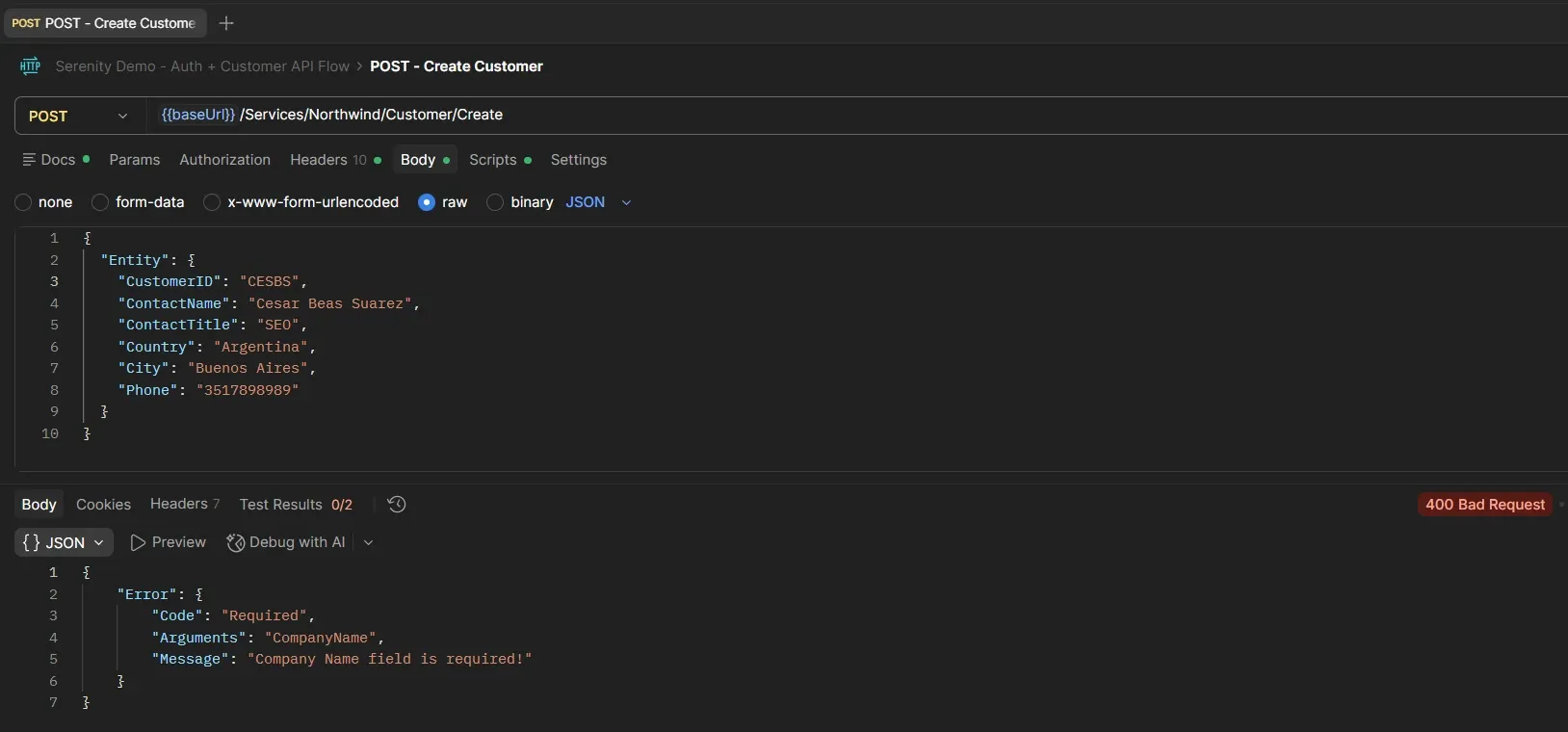
Sin CustomerID: 400 + "Customer Id field is required!"
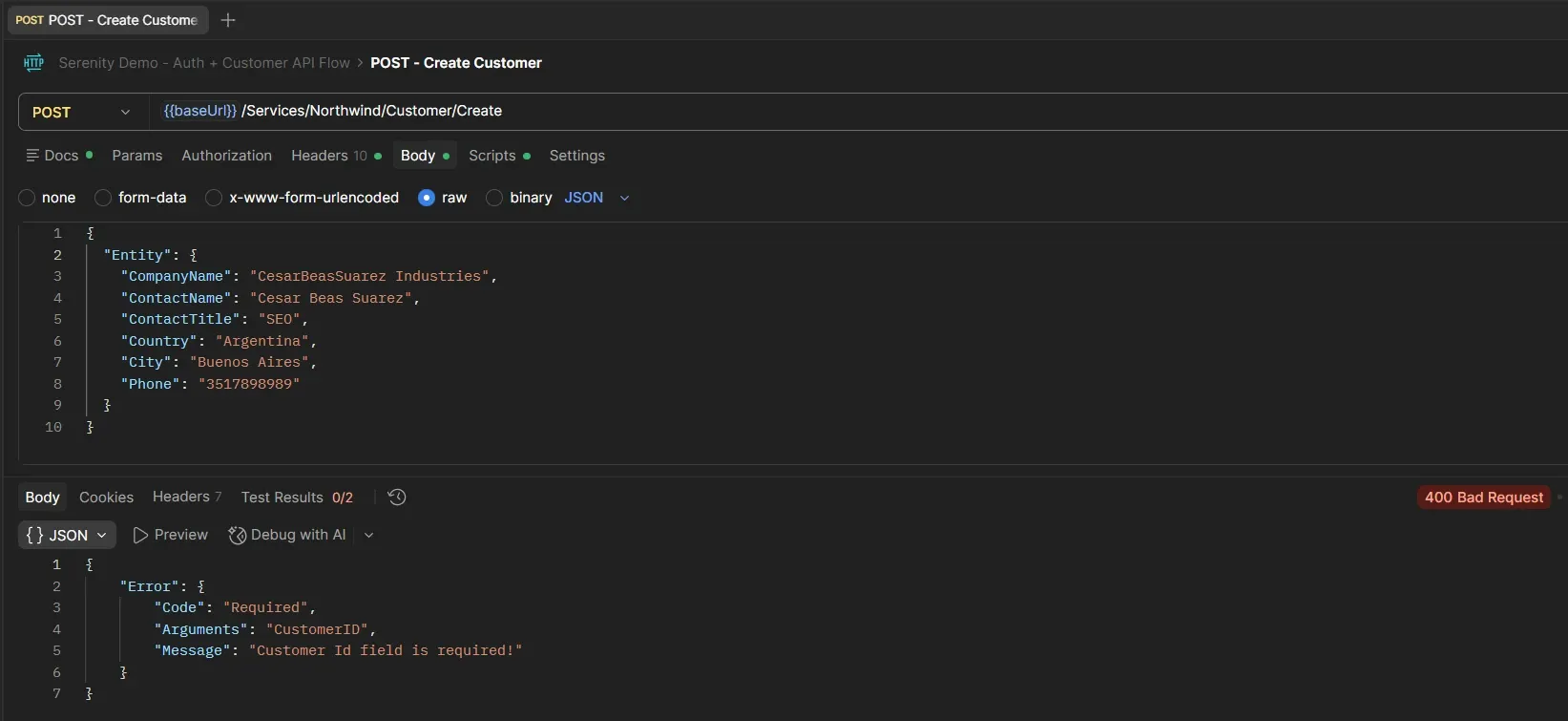
CustomerID duplicado (ALFKI): 400 + "Can't save record. There is another record with the same Customer Id value!"
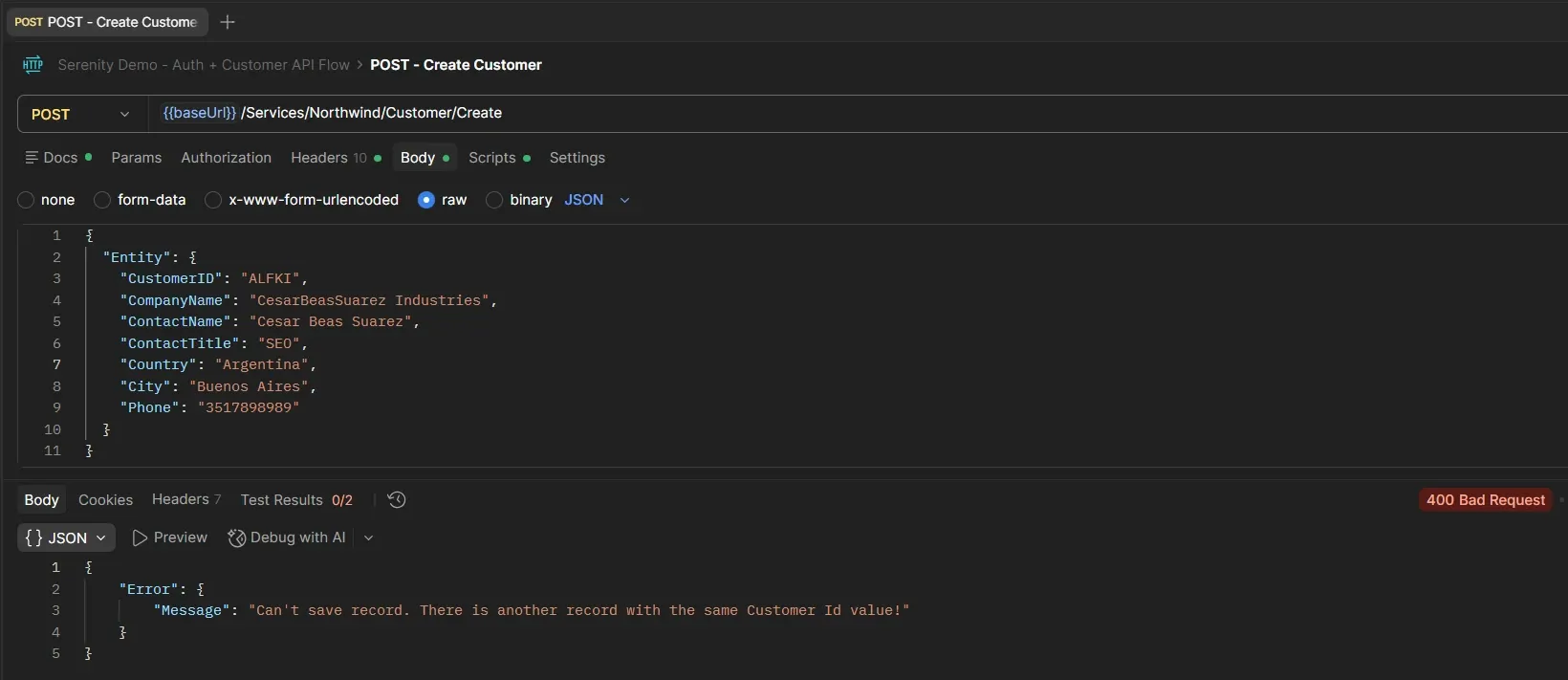
Los tres devuelven 400 con mensajes claros. La API valida bien. Con eso armé el CSV:
CustomerID,CompanyName,ContactName,ContactTitle,Country,City,Phone,UpdatedContactName,expected_status,test_type
TST01,Test Company One,John Doe,Manager,USA,New York,1234567890,John Doe UPDATED,200,valid
TST02,Test Company Two,Jane Smith,Director,Argentina,Buenos Aires,3517898989,Jane Smith UPDATED,200,valid
TST03,,John Doe,Manager,USA,New York,1234567890,,400,missing_company
,Test Company Four,John Doe,Manager,USA,New York,1234567890,,400,missing_id
ALFKI,Test Company Five,John Doe,Manager,USA,New York,1234567890,,400,duplicate

5 filas. 5 escenarios distintos:
- TST01 y TST02: datos válidos, esperamos 200. CRUD completo.
- TST03: sin CompanyName, esperamos 400. El Create falla, el resto se salta.
- Fila 4: sin CustomerID, esperamos 400.
- ALFKI: ID que ya existe en la base, esperamos 400.
Dos columnas clave: expected_status dice qué debería responder la API. test_type identifica el caso para el log.
UpdatedContactName es el valor que usa el Update — solo tiene sentido en las filas válidas.
Exportar colección y environment
Newman necesita los archivos JSON de la colección y del environment.
Colección: click derecho en "Serenity Demo - Auth + Customer API Flow" → Export → Collection v2.1.
Environment: click en los tres puntos de "serenity-demo" → Export.
Los guardé en D:\Proyectos\Testing\postman-api-testing\newman\.
El problema del baseUrl vacío
Corrí Newman por primera vez:
PS> newman run "Serenity Demo - Auth + Customer API Flow.postman_collection.json" -e "serenity-demo.postman_environment.json" -d "create_customer_data.csv" --folder Auth --folder "CRUD Happy Path"
Todo falló: Invalid URI "http:///Account/Login/". Tres barras. Newman no tenía el baseUrl.
Abrí el environment JSON. El valor de baseUrl estaba vacío:
{
"key": "baseUrl",
"value": "",
"type": "default",
"enabled": true
}
Postman exporta el "initial value" del environment, no el "current value". Como baseUrl se setea en runtime (o solo tenía current value), exportó vacío.
La solución: edité el JSON directo en Notepad++ y puse el valor:
"value": "https://demo.serenity.is",
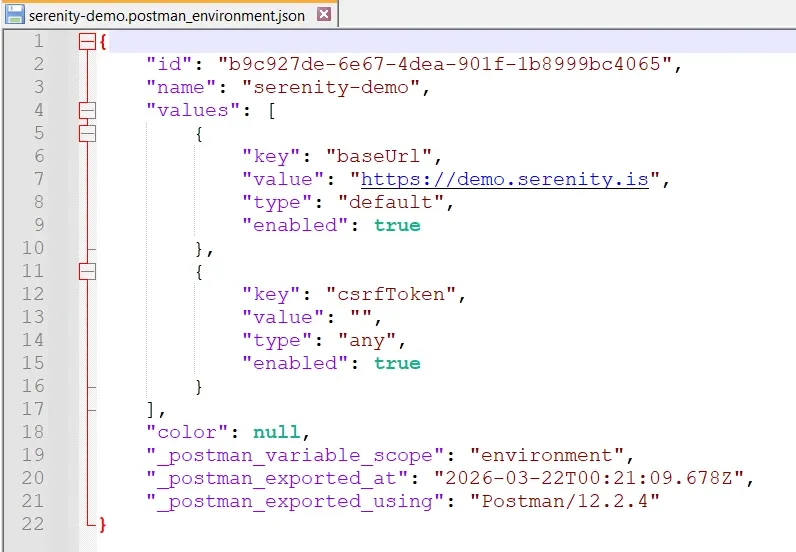
baseUrl con la URL de la API, y csrfToken que se llena dinámicamente después del login.Parametrizar todo el CRUD
El Create ya estaba parametrizado. Pero Retrieve, Update y Delete seguían hardcodeados con "CESBS". Cuando Newman corría iteraciones con TST01 o TST02, esas requests fallaban porque buscaban un cliente que no existía.
Parametricé todo:
Retrieve Customer — Body:
{
"EntityId": "{{CustomerID}}"
}
EntityId con el CustomerID de la iteración actual. Simple y directo.Update Customer — Body:
{
"Entity": {
"CustomerID": "{{CustomerID}}",
"CompanyName": "{{CompanyName}}",
"ContactName": "{{UpdatedContactName}}",
"ContactTitle": "{{ContactTitle}}",
"Country": "{{Country}}",
"City": "{{City}}",
"Phone": "{{Phone}}"
},
"EntityId": "{{CustomerID}}"
}
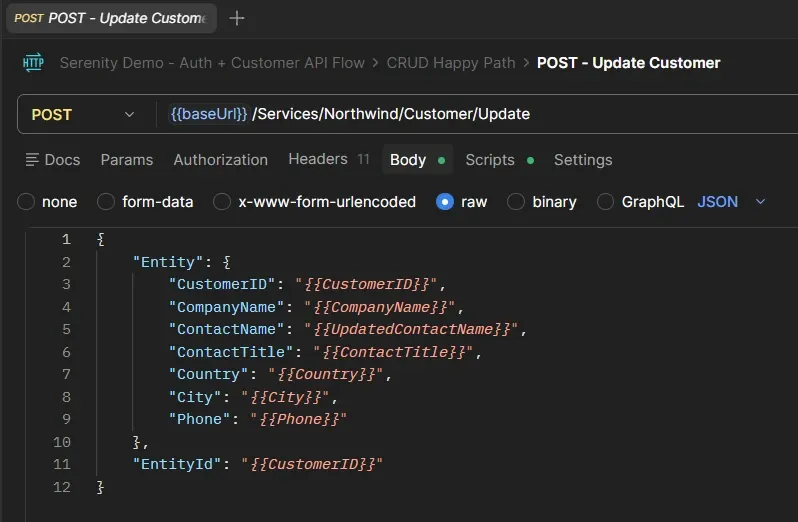
ContactName por {{UpdatedContactName}}. Incluye EntityId fuera del objeto Entity.Delete Customer — Body:
{
"EntityId": "{{CustomerID}}"
}
EntityId. Mismo patrón que el Retrieve: identifica al cliente y lo borra.Ahora todo el CRUD lee los datos del CSV.
El problema de las filas negativas
Fila TST03 tiene CompanyName vacío. El Create devuelve 400. Pero Retrieve, Update y Delete corren igual — Newman ejecuta todas las requests de la colección por cada iteración. No hay forma de "saltear" requests desde Newman.
Lo que sí puedo controlar es qué valido. Si el Create falló, no tiene sentido validar que el Retrieve devuelva 200 — el cliente nunca se creó.
La solución: un flag en el environment que conecta el resultado del Create con el resto del CRUD.
Assertions condicionales
Create Customer — Post-response
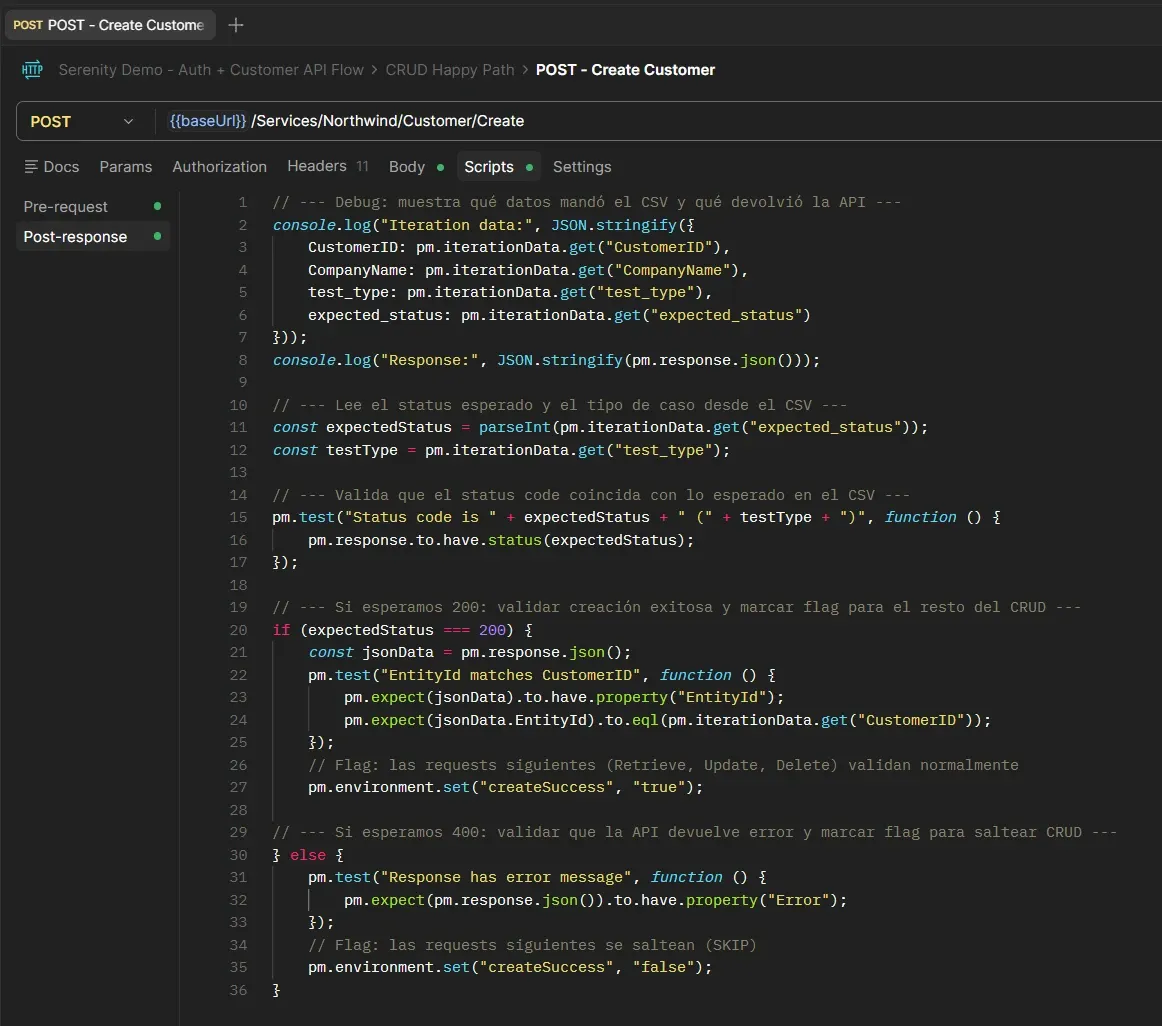
createSuccess = true. Si es 400, valida que haya error y setea el flag en false.Tres cosas pasan acá:
pm.iterationData.get("expected_status") lee el valor de la columna del CSV para esa iteración. No hay que configurar nada — Newman inyecta los datos automáticamente.
El nombre del test incluye el tipo de caso: "Status code is 200 (valid)" o "Status code is 400 (missing_company)". En el reporte ves exactamente qué caso es cada iteración.
pm.environment.set("createSuccess", "true") guarda un flag. Las requests siguientes lo leen para decidir si validan o se saltan.
Los console.log al inicio muestran en la terminal de Newman qué datos mandó el CSV y qué devolvió la API. Es el debugging más directo que hay en Postman — no hay breakpoints ni stepping como en un IDE. Es debugging por prints.
Customer List (Verify Create) — Post-response
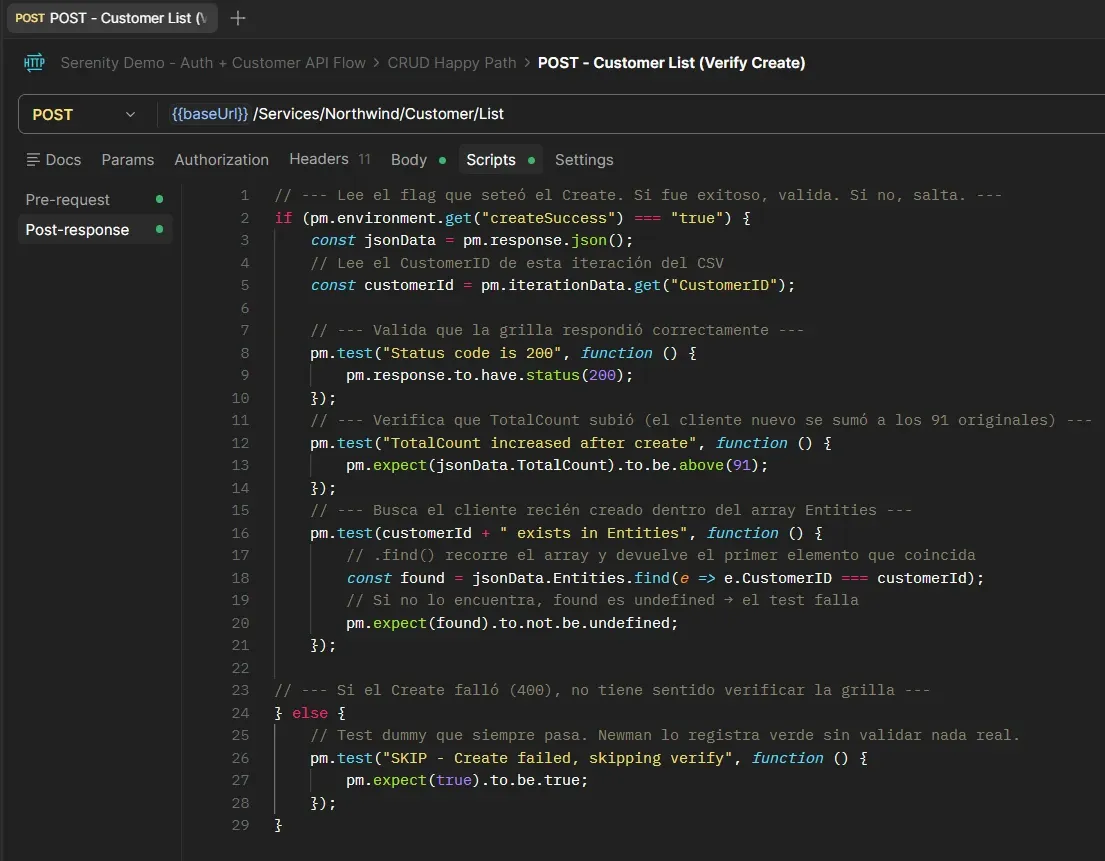
Si el Create fue exitoso, valida que el cliente aparezca en la grilla. Si falló, corre un test que siempre pasa — pm.expect(true).to.be.true — para que Newman lo registre como verde sin validar nada real.
Retrieve Customer — Post-response
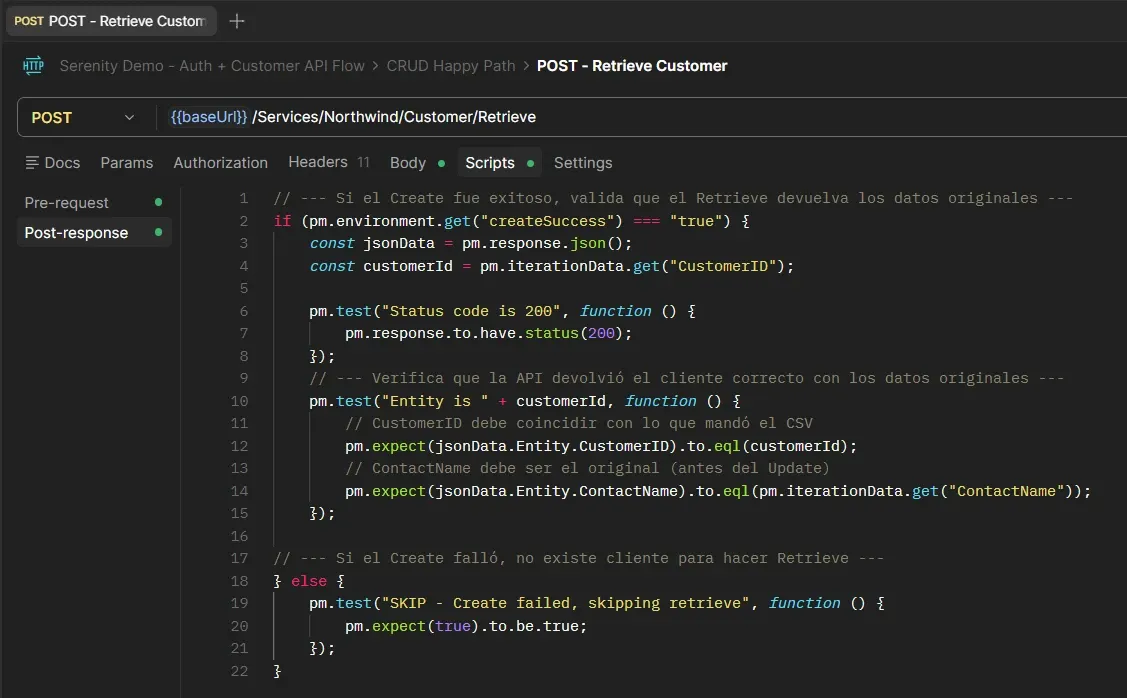
Update Customer — Post-response
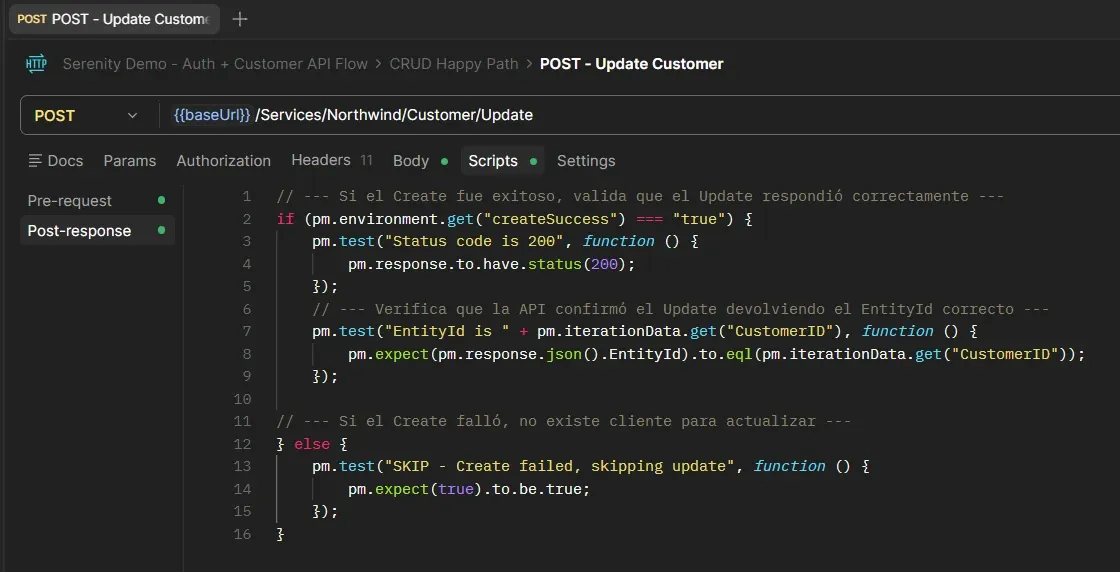
Retrieve Customer (Verify Update) — Post-response
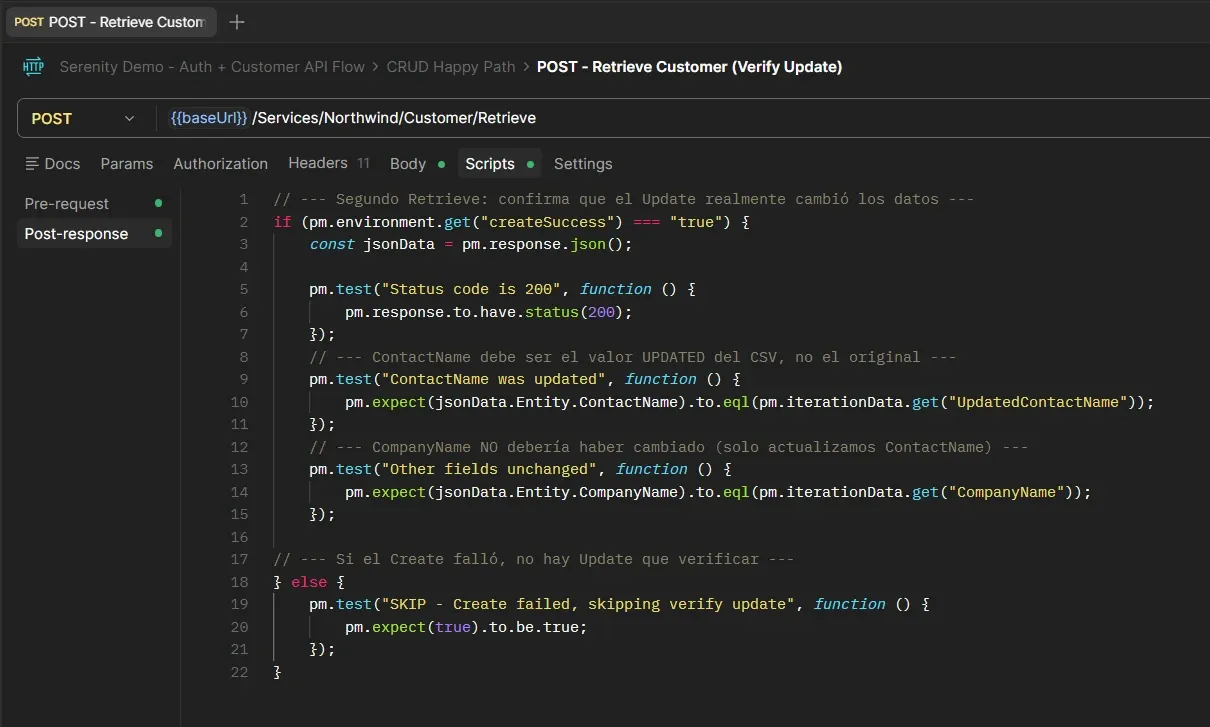
Delete Customer — Post-response
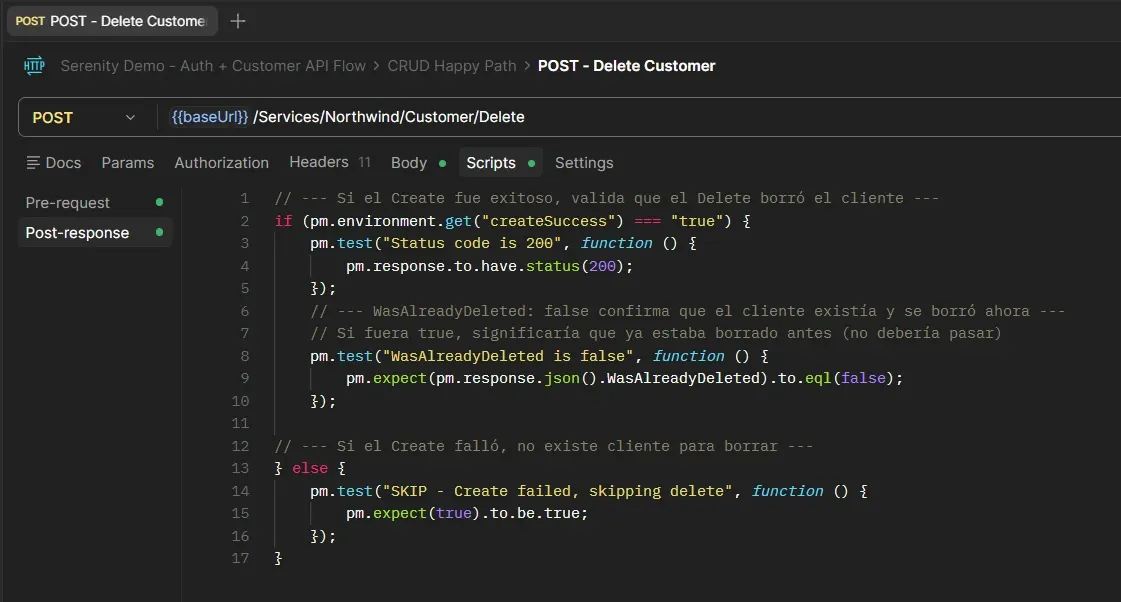
WasAlreadyDeleted: false. Si fuera true, significaría que el cliente ya estaba borrado antes del test.Customer List (Verify Delete) — Post-response
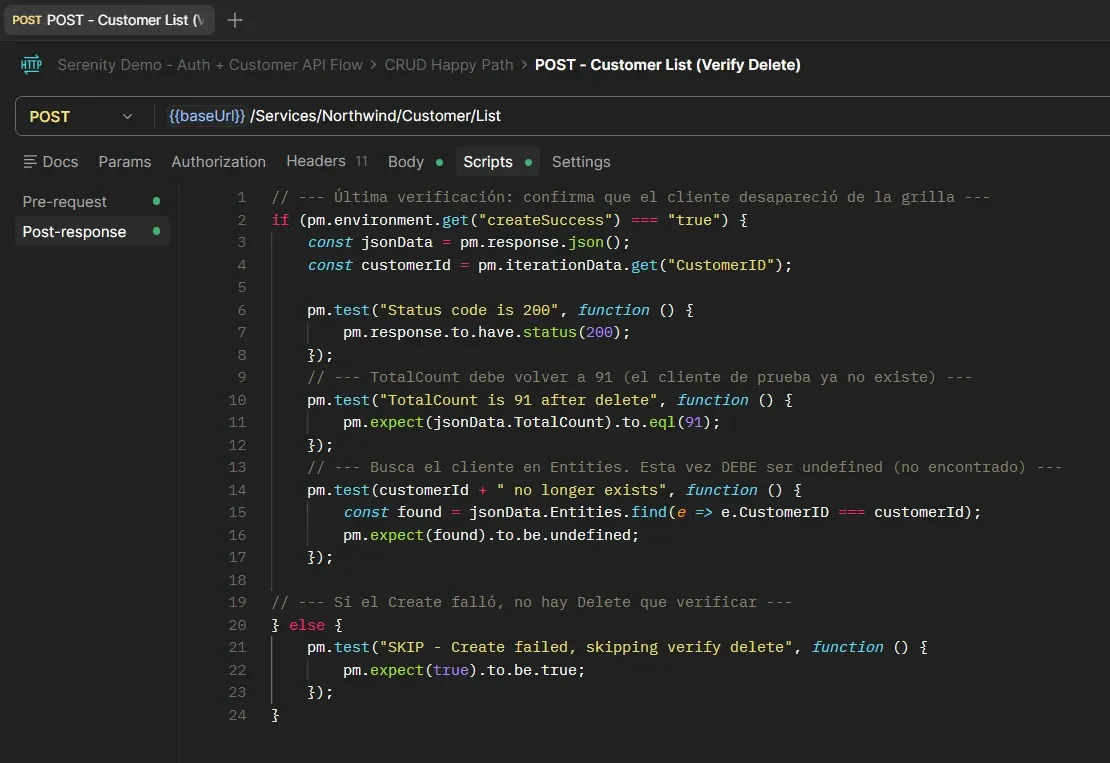
El patrón es el mismo en todas: leer createSuccess, validar si es "true", skipear si es "false".
Un detalle: Newman ejecuta TODAS las requests siempre. Lo que se salta es la validación, no la ejecución. Si querés saltear la request en sí, necesitás postman.setNextRequest() — más complejo y no era necesario para este caso.
Organización en folders
La colección tenía todas las requests en una lista plana. Antes de correr Newman, reorganicé en folders:
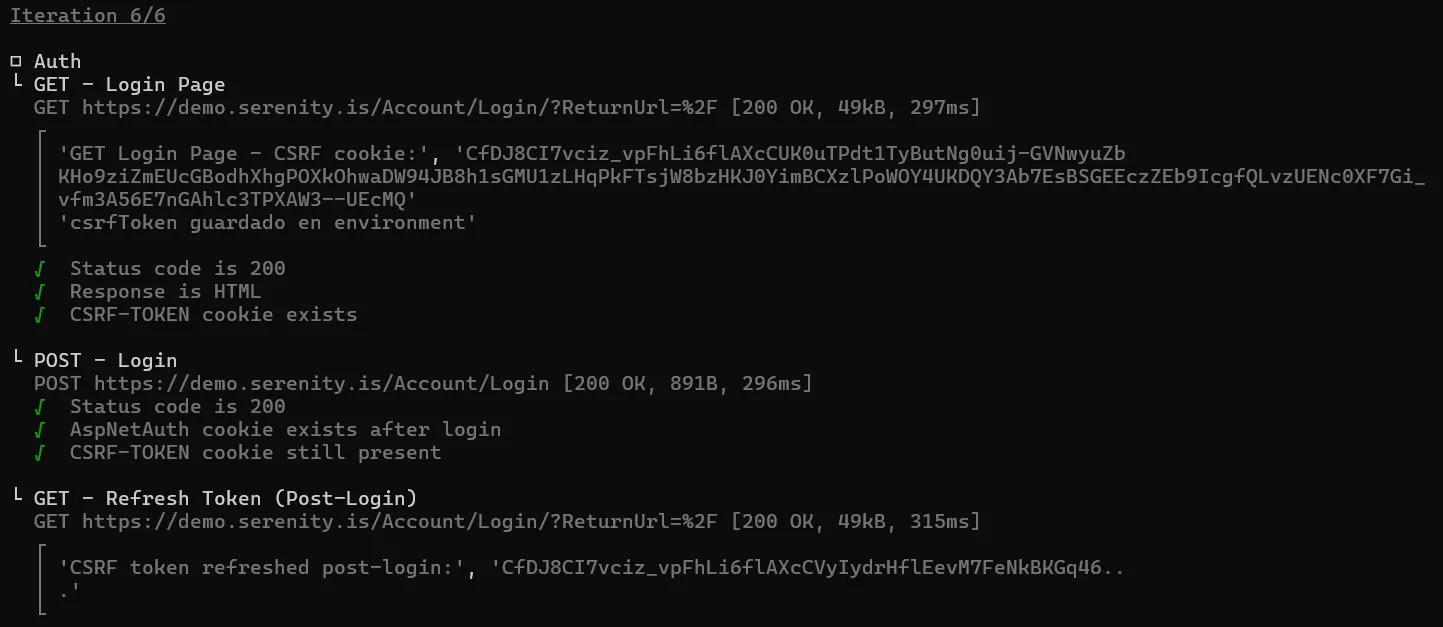
Auth — GET Login Page, POST Login, GET Refresh Token (Post-Login)
CRUD Happy Path — Customer List, Create Customer, Customer List (Verify Create), Retrieve Customer, Update Customer, Retrieve Customer (Verify Update), Delete Customer, Customer List (Verify Delete), Update Customer (Non-existent)
Negative Tests — Login (user correcto, pass mal), Login (user mal, pass correcta), Login (user y pass incorrectos), Login (user y pass vacios)
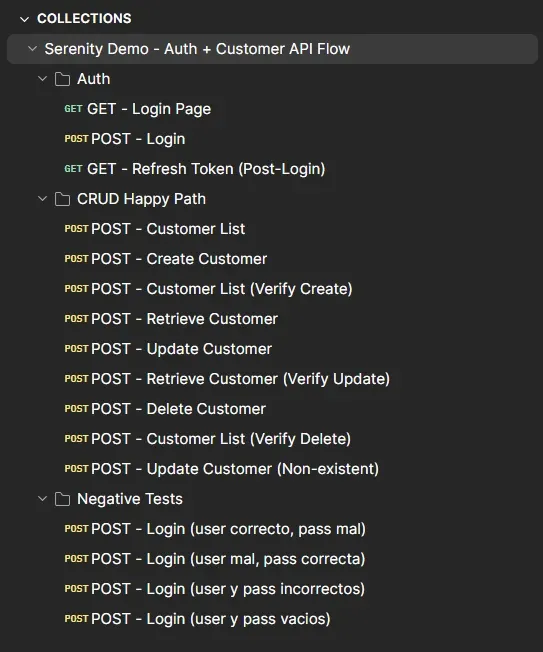
Newman acepta --folder para correr solo ciertos folders:
newman run collection.json --folder Auth --folder "CRUD Happy Path"
Eso corre Auth + CRUD Happy Path sin tocar Negative Tests.
El comando final
newman run "Serenity Demo - Auth + Customer API Flow.postman_collection.json" -e "serenity-demo.postman_environment.json" -d "create_customer_data.csv" --folder Auth --folder "CRUD Happy Path"
Qué hace cada parte:
newman run collection.json— corre la colección-e environment.json— usa el environment con baseUrl-d create_customer_data.csv— alimenta con el CSV (una iteración por fila)--folder Auth --folder "CRUD Happy Path"— solo esos folders
Para agregar el reporte HTML:
newman run collection.json -e env.json -d data.csv --folder Auth --folder "CRUD Happy Path" -r htmlextra
El reporte se genera en una carpeta newman/ con un archivo HTML timestamped.
La corrida
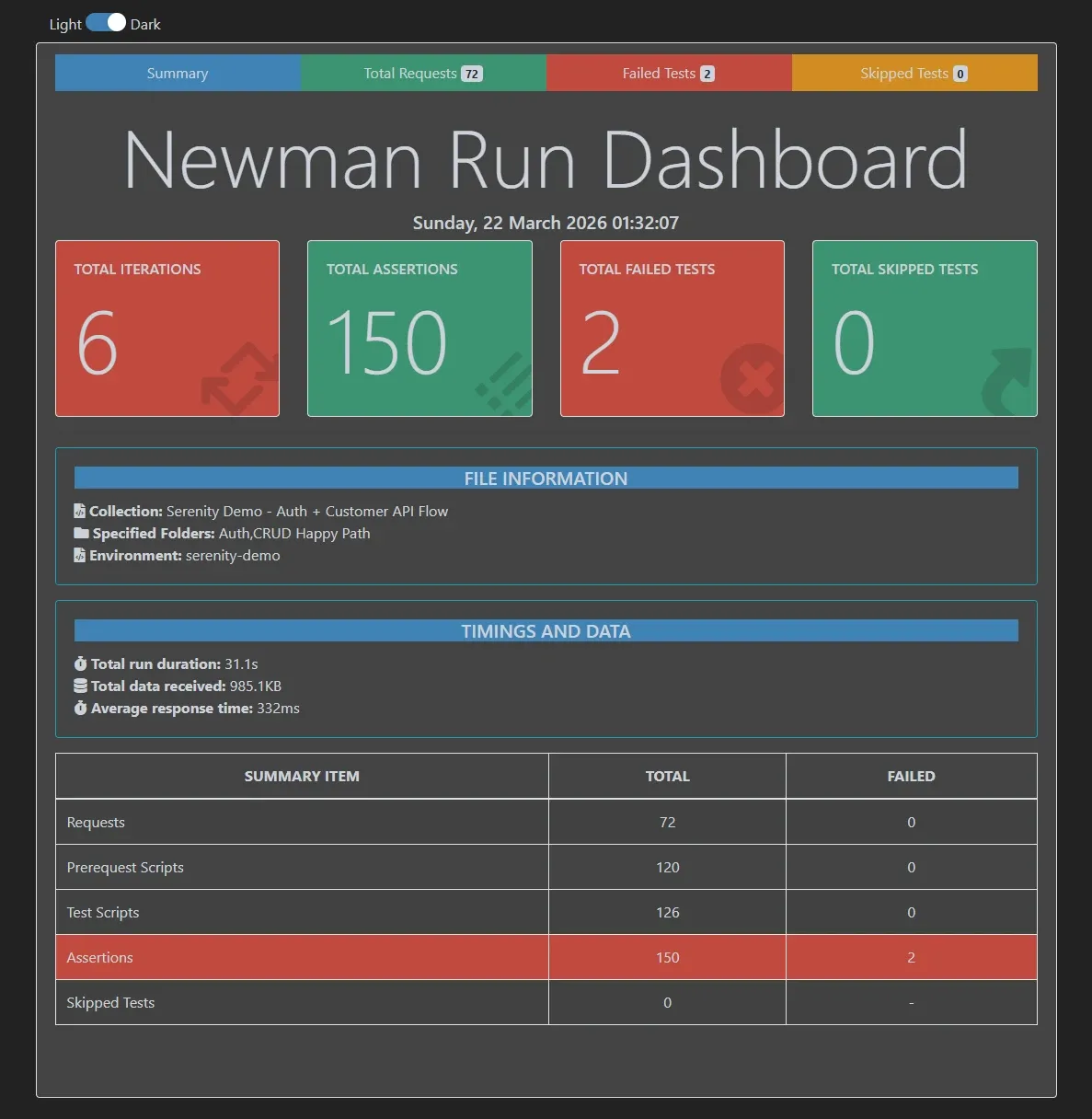
5 iteraciones. 150 assertions. Esto es lo que pasó:
Iteración 1: TST01 (valid)
Iteration data: {"CustomerID":"TST01","CompanyName":"Test Company One","test_type":"valid","expected_status":200}
Response: {"EntityId":"TST01"}
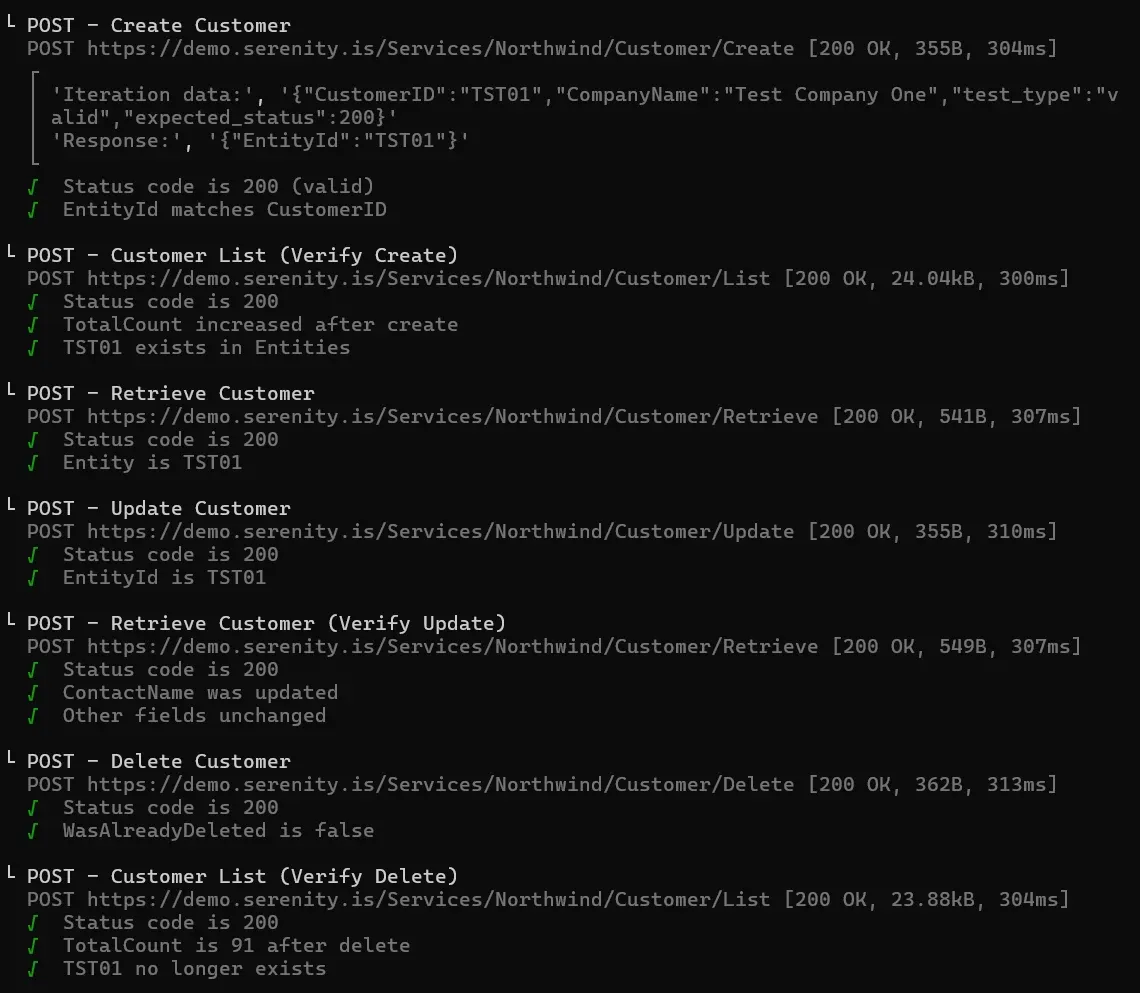
Create → 200 ✓. EntityId matches ✓. Verify Create → TotalCount increased ✓, TST01 exists ✓. Retrieve → Entity is TST01 ✓. Update → 200 ✓. Verify Update → ContactName was updated ✓, Other fields unchanged ✓. Delete → WasAlreadyDeleted is false ✓. Verify Delete → TotalCount is 91, TST01 no longer exists ✓.
CRUD completo. Cliente creado, verificado, actualizado, verificado de nuevo, borrado, verificado que no existe. Base limpia.
Iteración 2: TST02 (valid)
Mismo flujo con datos distintos. Argentina, Buenos Aires. Todo verde.
Iteración 3: TST03 (missing_company)
Iteration data: {"CustomerID":"TST03","CompanyName":"","test_type":"missing_company","expected_status":400}
Response: {"Error":{"Code":"Required","Arguments":"CompanyName","Message":"Company Name field is required!"}}
Create → 400 ✓ (missing_company). Response has error message ✓. El resto: SKIP todo ✓.
El Create falló como esperábamos. createSuccess se setea a "false". Verify Create, Retrieve, Update, Verify Update, Delete, Verify Delete — todos muestran "SKIP - Create failed" en verde.
Iteración 4: missing_id
Iteration data: {"CustomerID":"","CompanyName":"Test Company Four","test_type":"missing_id","expected_status":400}
Response: {"Error":{"Code":"Required","Arguments":"CustomerID","Message":"Customer Id field is required!"}}
Mismo patrón. 400 ✓. SKIP el resto ✓.
Iteración 5: ALFKI (duplicate)
Iteration data: {"CustomerID":"ALFKI","CompanyName":"Test Company Five","test_type":"duplicate","expected_status":400}
Response: {"Error":{"Message":"Can't save record. There is another record with the same Customer Id value!"}}
400 ✓. La API detecta el duplicado. SKIP el resto ✓.
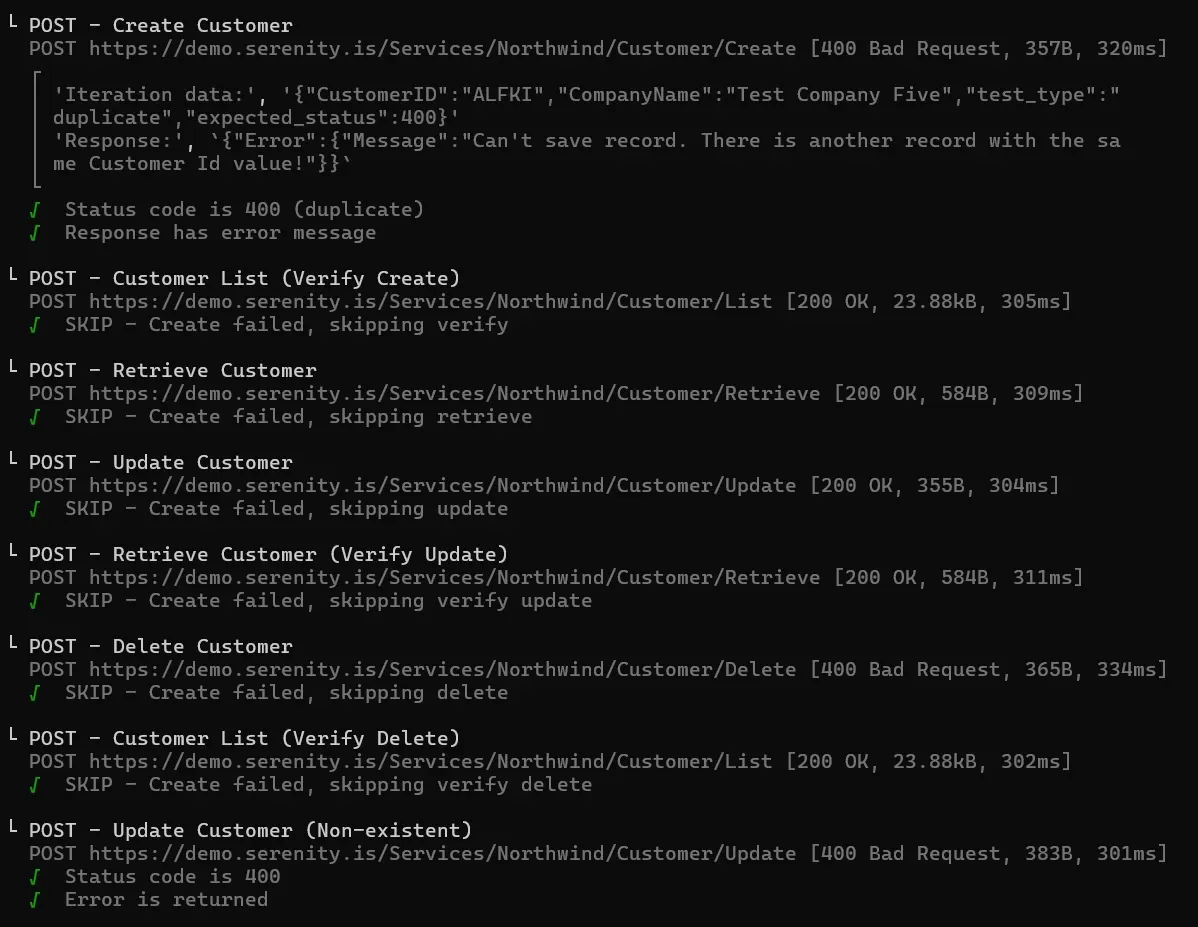
createSuccess hizo que el resto del ciclo se saltee con SKIP.El reporte HTML
Con -r htmlextra, Newman genera un dashboard.
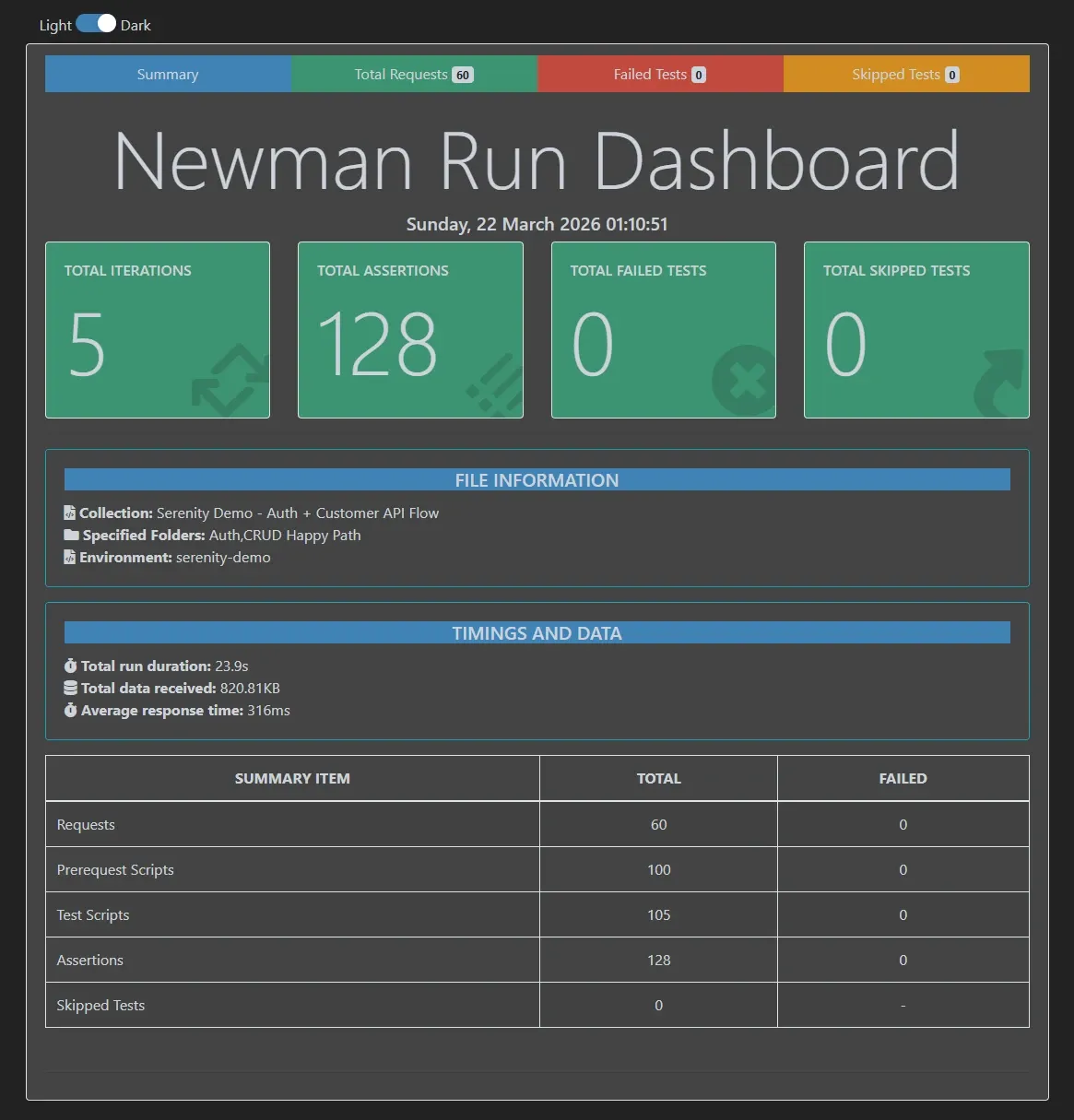
5 iteraciones. 128 assertions. 0 failures. Todo verde.
El reporte muestra: resumen general, detalle por iteración, tiempos de respuesta, requests que fallaron (ninguna), datos enviados y recibidos.
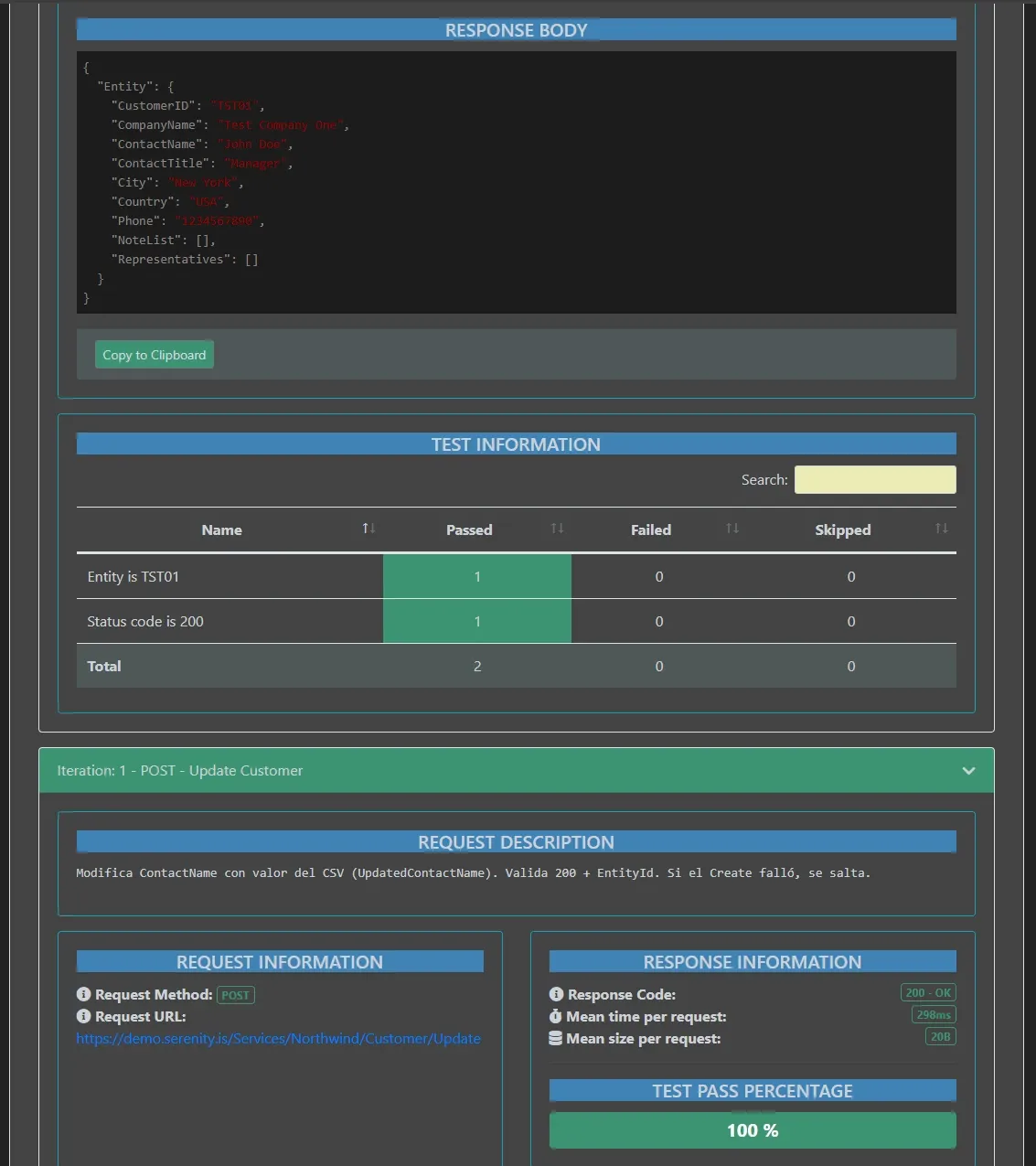
Romper a propósito
Un reporte verde no prueba que el sistema detecta problemas. Necesitaba demostrar que si los datos esperados no coinciden con la realidad, Newman lo atrapa. El mismo concepto que apliqué con Allure en Selenium — forzar failures para mostrar que el framework funciona.
Agregué una fila al CSV:
TST06,Bug Simulation Co,Test User,Tester,USA,Boston,5551234567,Test User UPDATED,400,forced_bug
Datos válidos, pero expected_status es 400. La API va a devolver 200 (creación exitosa), pero el test espera 400. Discrepancia forzada.
Resultado:
Iteration data: {"CustomerID":"TST06","CompanyName":"Bug Simulation Co","test_type":"forced_bug","expected_status":400}
Response: {"EntityId":"TST06"}
1. Status code is 400 (forced_bug)
expected response to have status code 400 but got 200
2. Response has error message
expected { EntityId: 'TST06' } to have property 'Error'
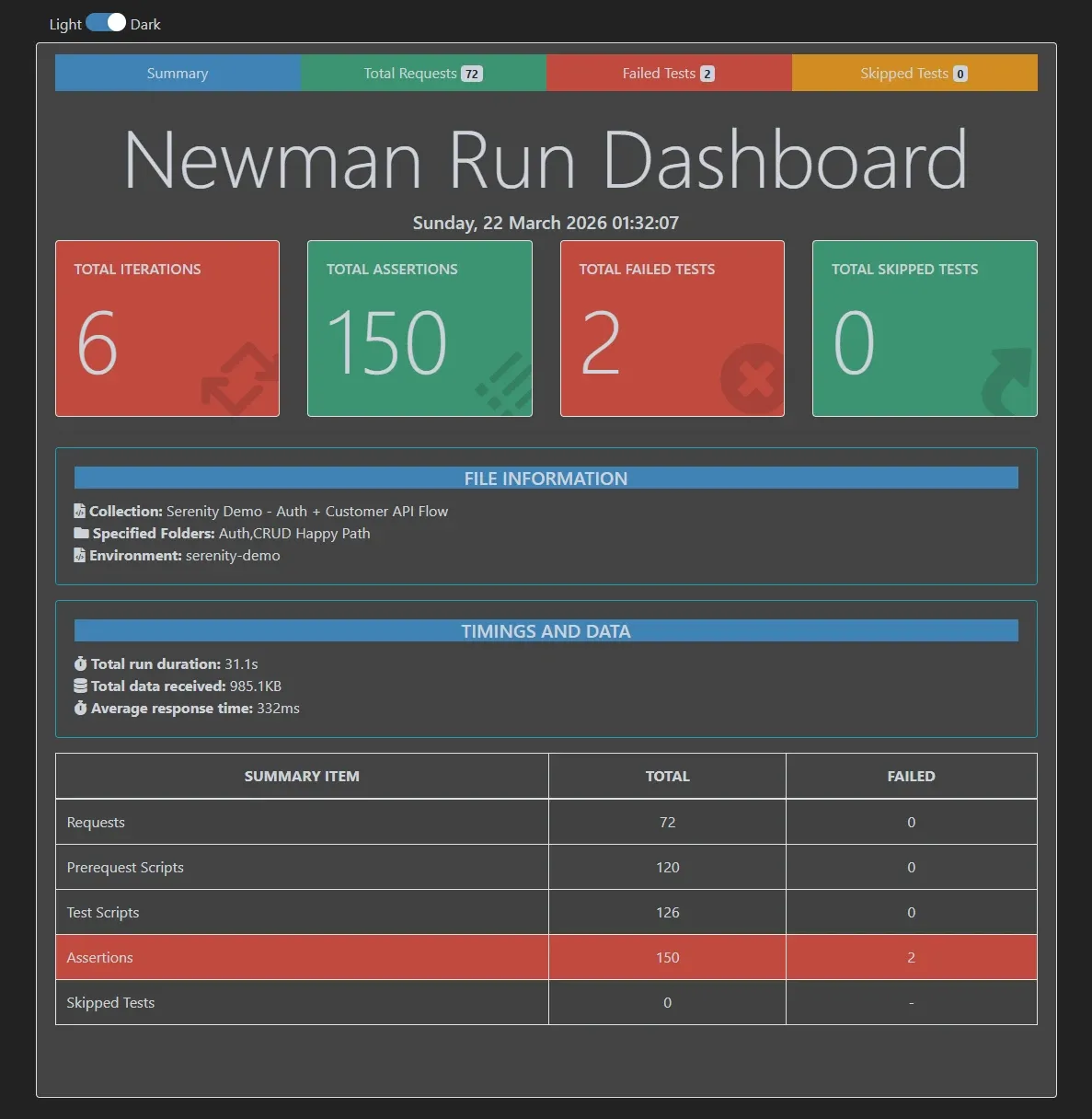
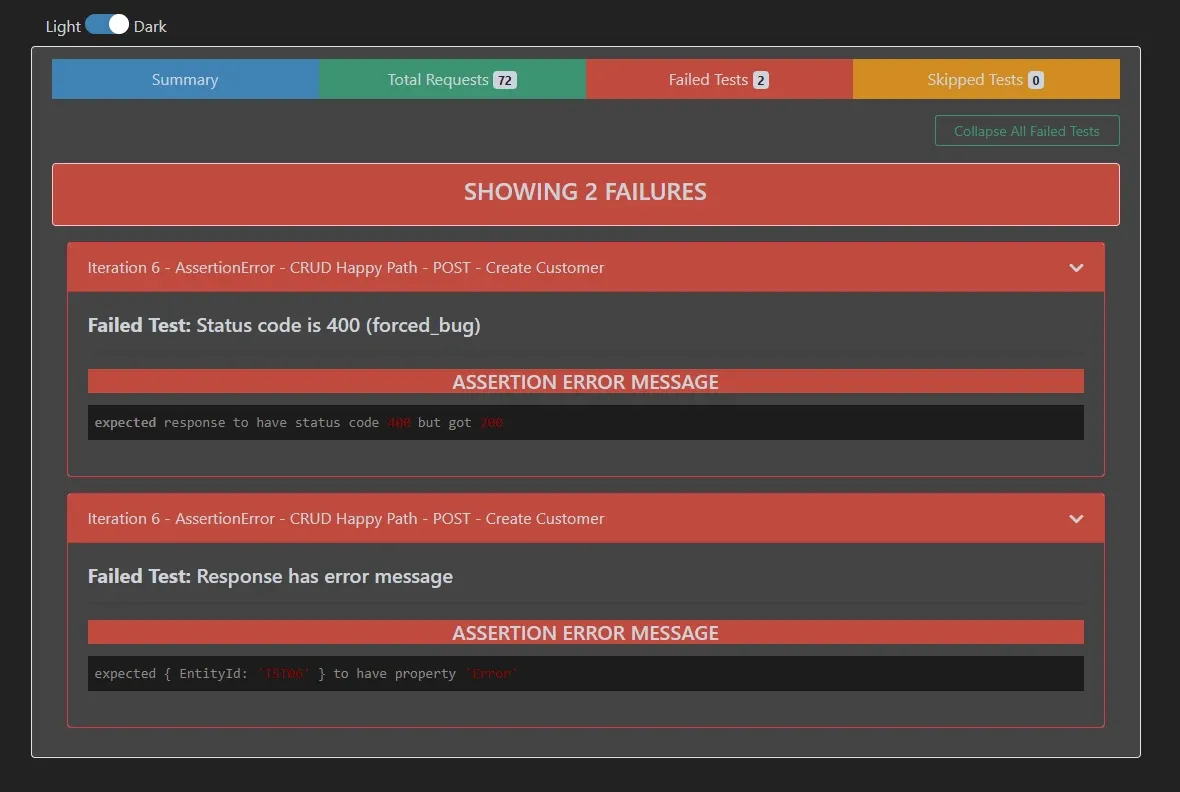
Newman lo atrapó. Dos failures, ambos en la iteración del forced_bug. Las otras 5 iteraciones siguen verdes.
El reporte muestra exactamente qué falló, en qué iteración, qué se esperaba y qué devolvió la API. Si esto fuera un bug real — por ejemplo, la API cambió un status code sin avisar — Newman lo detecta.
Errores que cometí
Environment exportado vacío
No me di cuenta hasta que vi las tres barras: http:///Account/Login. Postman exporta el "initial value", no el "current value". Si seteás variables en runtime, el export las pierde. La solución fue editar el JSON a mano.
Comentario con backticks rompió el script
Intenté agregar un comentario explicativo al inicio del Post-response del Create. Lo escribí con backticks (```). Postman interpretó eso como código y tiró TypeError: "" is not a function. El script nunca llegó a setear createSuccess, y todo el CRUD se salteó en todas las iteraciones. Costó un rato encontrarlo.
Script a nivel de folder que no debería estar
Había un pm.test("Status code is 200") en el script Post-response del folder "CRUD Happy Path". Ese script se aplica a TODAS las requests del folder automáticamente — incluyendo las que esperan 400. Eso generaba un "Status code is 200" duplicado y failures en los tests negativos. Lo borré.
Schema roto por datos del demo server
El schema de Customer List tiene campos required. Pero el demo server es público — otros usuarios crean clientes sin todos los campos. Entre corridas, aparecieron clientes sin Address y sin ContactName. El schema falló en esos. Tuve que sacar Address y ContactName del array de required. No es un error de los tests — es una realidad del demo server.
Debugging en Postman y Newman
Postman no tiene debugger paso a paso como IntelliJ. No hay breakpoints, no hay stepping. El debugging es con console.log() en los scripts.
En Postman: abrís la Console (abajo a la izquierda) y ves todo lo que logueás.
En Newman: aparece directamente en la terminal si corrés sin -r (sin reporter que suprima la salida).
Los console.log en el Create muestran exactamente qué datos mandó el CSV y qué devolvió la API:
Iteration data: {"CustomerID":"TST01","CompanyName":"Test Company One","test_type":"valid","expected_status":200}
Response: {"EntityId":"TST01"}
Eso es suficiente para debuggear. Si algo falla, ves el dato que mandaste y la response que recibiste.
Cómo conecta el CSV con las requests
No hay un script especial. Es una feature nativa de Newman. El flag -d create_customer_data.csv le dice a Newman: "por cada fila del CSV, corré toda la colección."
Las {{variables}} en los body se reemplazan por los valores de cada columna. {{CustomerID}} lee la columna CustomerID de esa fila.
En los scripts, pm.iterationData.get("CustomerID") accede al mismo valor. Así los tests comparan contra los datos de esa iteración específica.
5 filas = 5 iteraciones. Cada iteración corre Auth + CRUD Happy Path completo. Si una fila tiene datos inválidos, el Create falla, createSuccess se pone en "false", y el resto del CRUD se salta.
Estado actual
El comando para correr todo:
newman run "Serenity Demo - Auth + Customer API Flow.postman_collection.json" -e "serenity-demo.postman_environment.json" -d "create_customer_data.csv" --folder Auth --folder "CRUD Happy Path" -r htmlextra
Lo que valida por iteración válida (200):
- Customer List — 91 registros, schema, campos obligatorios
- Create Customer — 200 + EntityId correcto
- Customer List (Verify Create) — TotalCount subió + cliente existe
- Retrieve Customer — datos originales correctos
- Update Customer — 200 + EntityId
- Retrieve Customer (Verify Update) — ContactName cambió + otros campos intactos
- Delete Customer — 200 + WasAlreadyDeleted: false
- Customer List (Verify Delete) — TotalCount volvió a 91 + cliente no existe
- Update Customer (Non-existent) — 400 + Error
Lo que valida por iteración inválida (400):
- Customer List — igual
- Create Customer — 400 + Error message 3-8. SKIP — "Create failed, skipping..."
- Update Customer (Non-existent) — 400 + Error
Archivos en el repo:
postman-api-testing/
└── newman/
├── Serenity Demo - Auth + Customer API Flow.postman_collection.json
├── serenity-demo.postman_environment.json
├── create_customer_data.csv
└── newman/
└── [reportes HTML generados]
Takeaways
Postman Runner cobra por data files. Newman lo hace gratis y además permite CI/CD. Para data-driven testing profesional, Newman es el camino.
Exportar el environment no incluye "current values". Si las variables se setean en runtime, hay que editar el JSON a mano o usar --env-var en el comando.
createSuccess como flag entre requests funciona. Las requests se ejecutan siempre — lo que se controla es la validación. Para saltear la ejecución en sí se necesitaría postman.setNextRequest().
Los console.log son el debugger de Postman. No hay breakpoints. Es debugging por prints.
Scripts a nivel de folder se aplican a todas las requests. Si tenés un test genérico ahí, va a correr donde no debería.
Forzar failures a propósito es tan importante como hacer que todo pase. Si nunca ves rojo, no sabés si el sistema detecta problemas.
Newman corre toda la selección por cada fila del CSV. Auth se repite 6 veces aunque solo necesita correr una. Con 6 filas no importa. Con 100 sería un problema. La solución real para escala es un framework basado en código como REST Assured, donde controlás el flujo completo. Newman es para colecciones moderadas.
Próximo paso
Newman corre en mi máquina. El siguiente nivel es que corra solo: CI/CD con GitHub Actions. Push al repo, el pipeline ejecuta Newman, el reporte aparece automático.