Sesión 7 de mi lab de Selenium + Java: Page Object Model — por qué separar Pages de Tests
La Page interactúa con la UI, el Test decide si está bien o mal. Anatomía de LoginPage, DashboardPage, validaciones con check.java y logs claros.
Qué es Page Object Model
POM es un patrón de diseño, no una librería.
La idea central es simple:
👉 Cada página (o vista importante) de la aplicación se representa como una clase.
👉 Esa clase conoce cómo interactuar con la UI.
👉 Luego los tests solo dicen qué quieren validar, no cómo se hace.
En POM:
- los selectores viven en las páginas
- las acciones viven en las páginas
- las esperas viven en las páginas
- los tests no usan
ByniWebElementdirectamente
El problema que POM viene a resolver
Un test sin POM suele verse así:
driver.findElement(By.id("LoginPanel0_Username")).sendKeys("admin");
driver.findElement(By.id("LoginPanel0_Password")).sendKeys("serenity");
driver.findElement(By.id("LoginPanel0_LoginButton")).click();
String title = driver.findElement(By.cssSelector("h1")).getText();
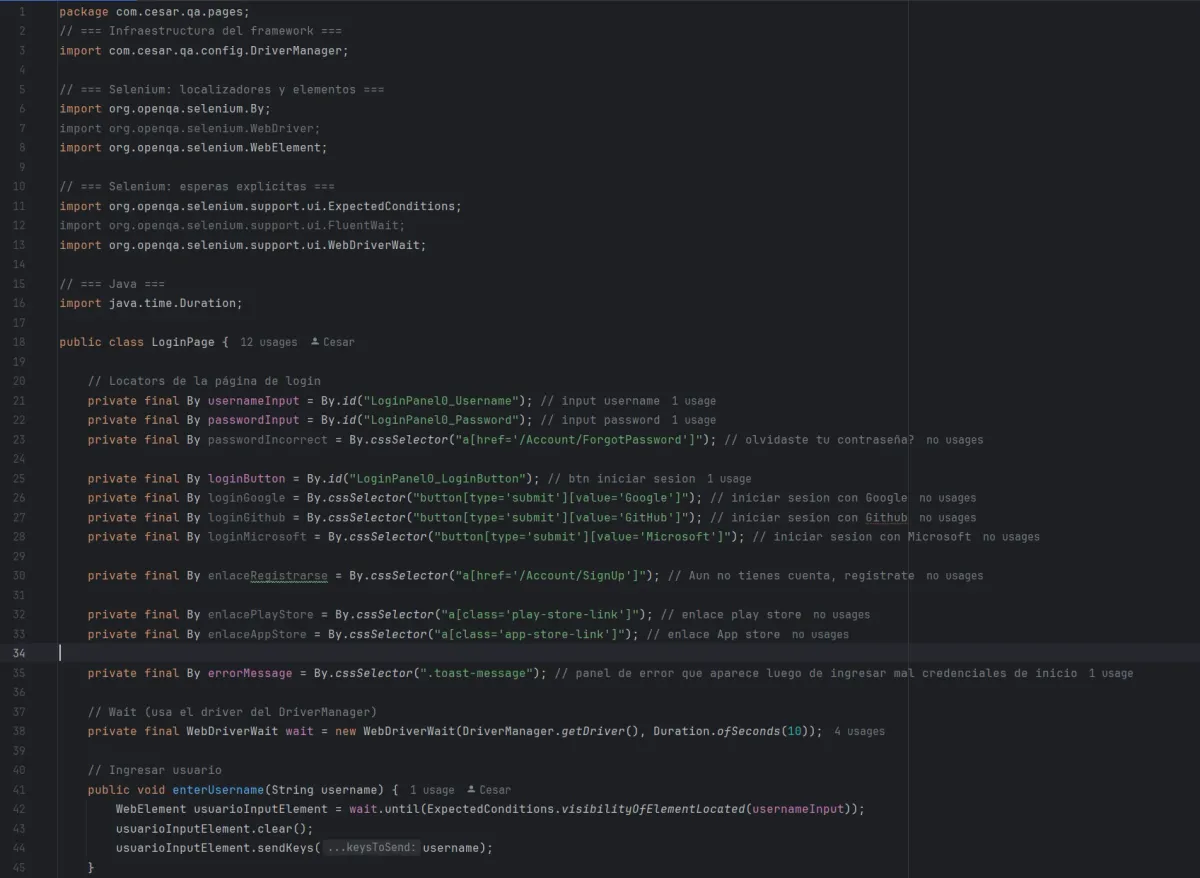
assertEquals(title, "Tablero");Esto tiene varios problemas:
- el test sabe demasiado de la UI
- si cambia un ID, hay que tocar todos los tests
- la intención del test no se lee fácil
- mezclar validaciones + navegación + selectores hace ruido
La idea clave de POM
Con POM, el test debería leerse así:
LoginPage loginPage = new LoginPage();
loginPage.loginComo("admin", "serenity");
DashboardPage dashboard = new DashboardPage();
check.visible(dashboard.estaVisible(), "Dashboard visible luego de login válido");
check.equals(dashboard.obtenerTitulo(), "Tablero", "Título del dashboard");El test narra una historia, no ejecuta Selenium.
Estructura general del proyecto
Como va mi prj:
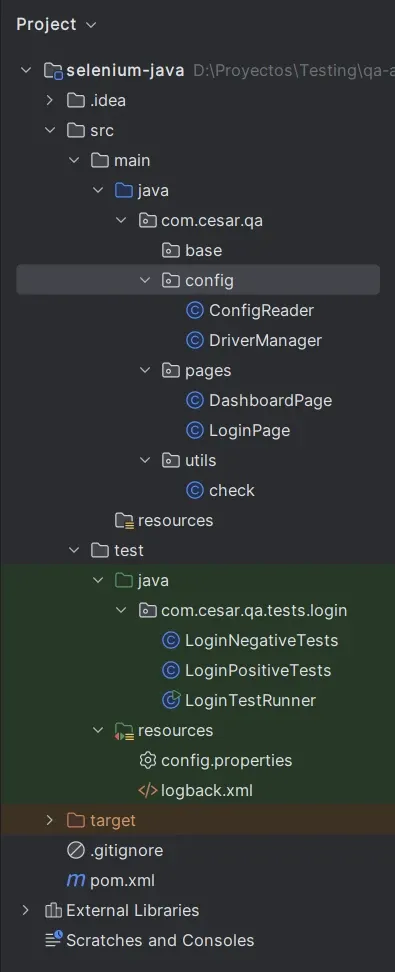
src/main/java
com.cesar.qa
├─ config
│ ├─ ConfigReader
│ └─ DriverManager
├─ pages //Pages object model
│ ├─ DashboardPage
│ └─ LoginPage
└─ utils
└─ check
src/test/java
com.cesar.qa.tests.login //Tests
├─ LoginPositiveTests
├─ LoginNegativeTests
└─ LoginTestRunnerQué contiene una Page (ejemplo real)
LoginPage.java
Una Page no valida resultados finales.
Solo sabe interactuar con la página.
Así armé page del Login:
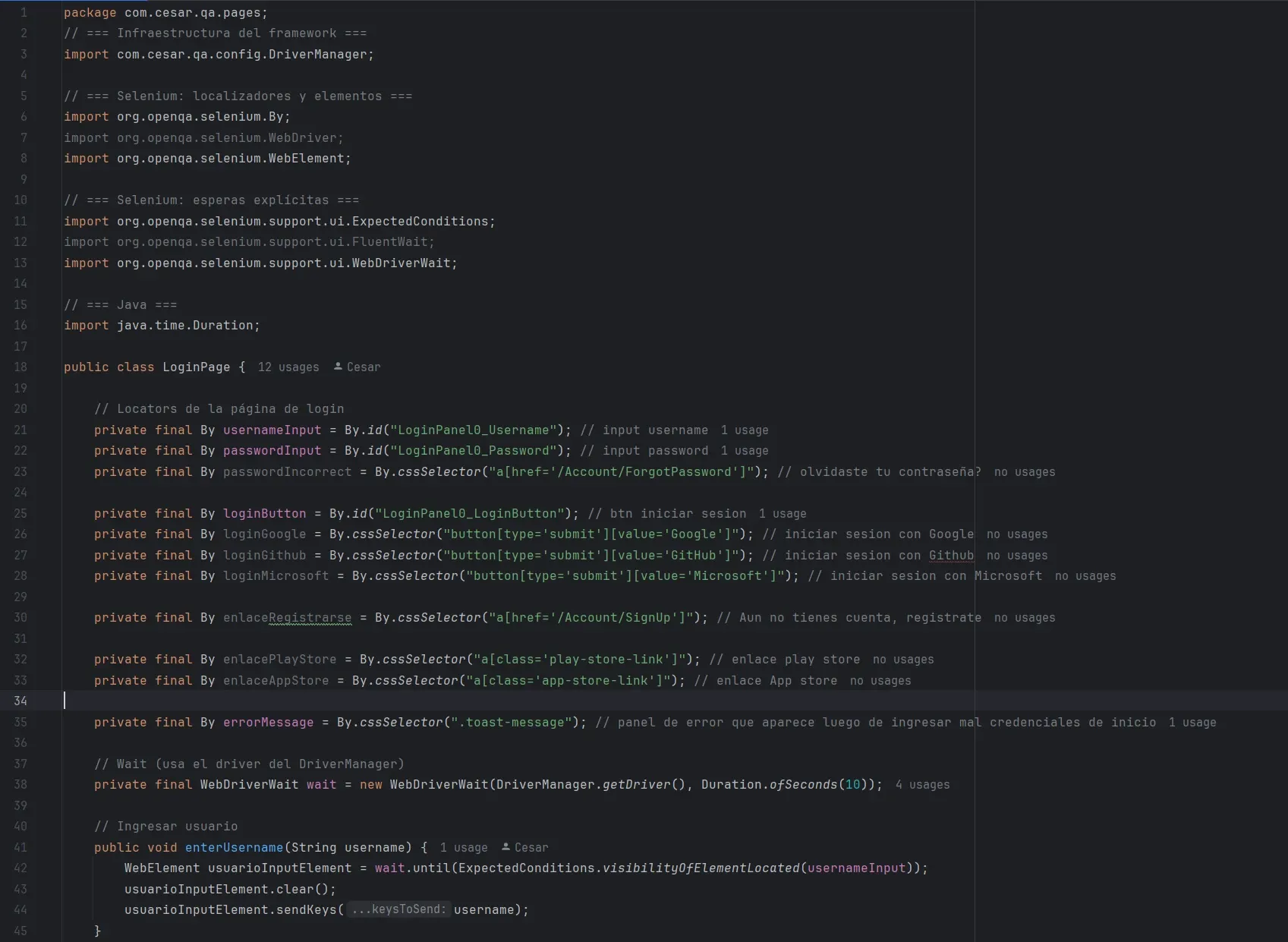
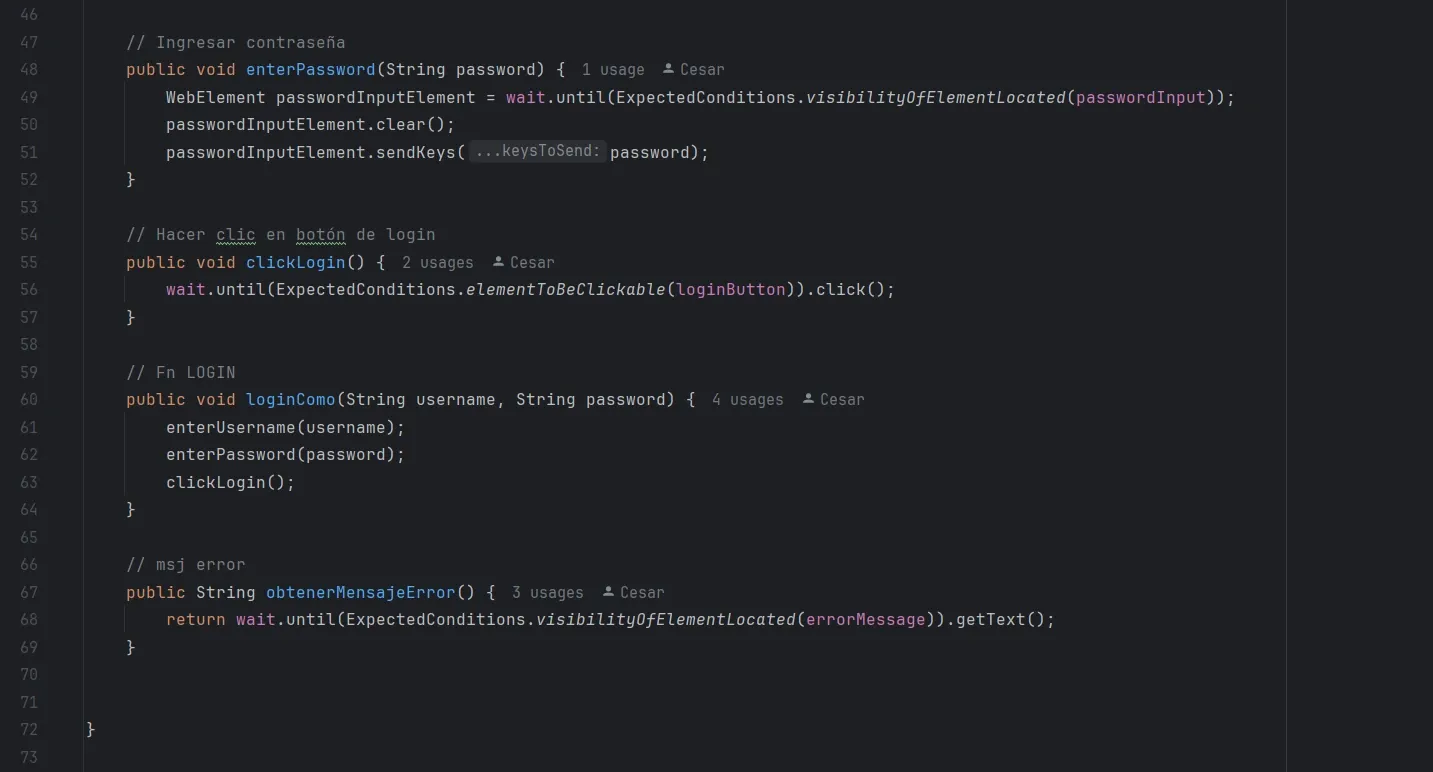
📌 Importante
La Page:
- no hace asserts
- no imprime logs
- no decide si algo es correcto o no
Solo devuelve datos o estados.
Anatomía de una Page Object (LoginPage)
Una Page Object no es solo “una clase con selectores”.
Es una pieza estructural del framework y tiene reglas claras sobre qué debe contener y qué no.
Voy a desglosar LoginPage por partes y explicar por qué está hecha así.
Imports: qué importa una Page Object (y qué no)
Una Page Object debería importar solo lo necesario para interactuar con la UI, nada más.
Ejemplo típico de imports correctos:
// Infraestructura del framework
import com.cesar.qa.config.DriverManager;
// Selenium: localizadores y elementos
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
// Selenium: esperas explícitas
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
// Java
import java.time.Duration;Qué sí debe importar una Page
By,WebElement→ porque conoce el DOMWebDriverWait,ExpectedConditions→ porque maneja esperasDriverManager→ para leer el driver ya inicializado
Qué no debe importar una Page
❌ TestNG / JUnit
❌ asserts
❌ clases de test
❌ lógica de negocio
❌ no debe navegar a URLs
❌ inicialización o cierre del driver
📌 Regla mental
Si un import tiene que ver con ejecución de pruebas o validación, no va en una Page.
La Page interactúa.
El test decide si algo está bien o mal.
Locators: pocos, importantes y bien definidos
En una Page Object, los locators son contratos con la UI.
private final By usernameInput = By.id("LoginPanel0_Username");
private final By passwordInput = By.id("LoginPanel0_Password");
private final By loginButton = By.id("LoginPanel0_LoginButton");
private final By errorMessage = By.cssSelector(".toast-message");Por qué private
- Nadie fuera de la Page debería acceder a los selectores
- El test no tiene que saber cómo está construido el DOM
- Si el selector cambia, solo se cambia acá
Por qué final
- Un locator no debería mutar
- Representa un elemento fijo de la UI
- Evita errores accidentales y refuerza la idea de “contrato”
📌 Idea clave
Si mañana cambia la UI por una nueva versión,
este es el archivo al que se viene primero.
Por eso:
- conviene tener solo los locators relevantes
- bien nombrados
- ordenados
- y no duplicados
Esperas: por qué viven en la Page
En este proyecto se usa WebDriverWait, y no Thread.sleep.
private final WebDriverWait wait =
new WebDriverWait(DriverManager.getDriver(), Duration.ofSeconds(10));Por qué WebDriverWait
- espera condiciones reales, no tiempo fijo
- hace los tests más estables
- evita flakiness innecesaria
Por qué la Page 'lee' el driver y no lo crea
[Test]
|
| 1) initDriver()
| 2) get(baseUrl)
v
[DriverManager]
|
| getDriver()
v
[Page Object]
|
| interactúa con UI
| (click, sendKeys, getText, isVisible)
v
[Browser / DOM]La Page asume que:
- el driver ya fue inicializado en otro lugar
- la URL ya fue abierta en otro lugar
Esto es intencional.
Si una Page:
- inicializara el driver
- o navegara a una URL
entonces rompería el POM, porque:
- ya no sería reutilizable
- mezclaría responsabilidades
- sería imposible controlar flujos desde los tests
✅ Diagrama correcto (responsabilidades separadas)
DriverManager ──► Infraestructura
Test ──► Flujo y validación
Page ──► Interacción UICada pieza:
- hace una sola cosa
- la hace bien
- no invade a las demás
El Page Object Model no trata de dónde escribir código,
sino de quién debe tomar cada decisión.
Métodos de acción: cómo interactúa la Page
Los métodos de una Page son acciones atómicas o acciones compuestas.
Acciones simples
public void enterUsername(String username) {
WebElement el =
wait.until(ExpectedConditions.visibilityOfElementLocated(usernameInput));
el.clear();
el.sendKeys(username);
}Este método:
- espera que el elemento exista
- limpia el campo
- escribe el valor
- oculta toda la complejidad al test
El test no sabe:
- cómo se localiza el input
- qué espera se usa
- si hay que limpiar o no
Solo dice: “ingresar usuario”.
Acciones compuestas
public void loginComo(String user, String pass) {
enterUsername(user);
enterPassword(pass);
clickLogin();
}Esto permite que los tests sean expresivos:
loginPage.loginComo("admin", "serenity");Y no una secuencia de pasos técnicos.
Métodos de estado: devolver información al test
Una Page también puede devolver estados, no solo ejecutar acciones.
Ejemplo:
public String obtenerMensajeError() {
return wait.until(
ExpectedConditions.visibilityOfElementLocated(errorMessage)
).getText();
}Acá la Page:
- obtiene información
- pero no decide si es correcta o no
La validación vive en el test.
Métodos “safe”: pensar en tests negativos
Para escenarios negativos, a veces esperar algo es incorrecto.
Ejemplo:
Si el login falla, el dashboard no debería aparecer.
Para eso se crean métodos seguros:
public boolean estaVisibleSafe() {
try {
wait.until(ExpectedConditions.visibilityOfElementLocated(dashboardBody));
return true;
} catch (Exception e) {
return false;
}
}Esto permite:
- validar ausencia de navegación
- evitar que el test explote por timeout
- escribir tests negativos claros
check.isFalse(
dashboard.estaVisibleSafe(),
"El dashboard NO debería aparecer"
);📌 Esto es diseño consciente, no un hack.
Resumen mental de una Page Object
Una Page Object:
- ✔ importa solo Selenium + infraestructura
- ✔ tiene locators
private final - ✔ usa esperas explícitas
- ✔ no inicializa driver
- ✔ no navega a URLs
- ✔ no valida resultados finales
- ✔ devuelve estados o ejecuta acciones
- ✔ protege al test de cambios de UI
Page Object vs Test
Separación de responsabilidades en POM
Una de las ideas centrales del Page Object Model es separar responsabilidades.
La Page interactúa con la UI.
El Test decide si el comportamiento es correcto.
La siguiente tabla resume qué va en cada uno y por qué:
| Concepto | Page Object (LoginPage, DashboardPage) | Test (LoginPositiveTests, etc.) |
|---|---|---|
| Responsabilidad principal | Interactuar con la UI | Verificar comportamiento |
| Conocimiento del DOM | ✅ Sí | ❌ No |
Selectores (By) | ✅ Sí | ❌ No |
Esperas explícitas (WebDriverWait) | ✅ Sí | ❌ No |
| Acciones (click, sendKeys, getText) | ✅ Sí | ❌ No |
| Estados (visible, texto, existe) | ✅ Devuelve | ❌ No calcula |
| Validaciones (asserts, checks) | ❌ No | ✅ Sí |
| Decisión de OK / FAIL | ❌ No | ✅ Sí |
Navegar a URLs (driver.get) | ❌ No | ✅ Sí |
| Inicializar / cerrar driver | ❌ No | ✅ Sí |
| Flujo de negocio | ❌ No | ✅ Sí |
| Uso de frameworks de test (TestNG, JUnit) | ❌ No | ✅ Sí |
Regla de oro mental
La Page responde “qué hay y qué puedo hacer”
El Test responde “esto está bien o está mal”
Si una Page:
- valida resultados
- lanza asserts (validaciones)
- decide si algo falló
➡️ dejó de ser una Page y se volvió un test mal ubicado.
Ejemplo práctico
❌ Mal (validación dentro de la Page)
public void validarTituloDashboard() {
String titulo = driver.findElement(...).getText();
if (!titulo.equals("Tablero")) {
throw new RuntimeException("Error");
}
}Problemas:
- la Page decide el resultado
- no es reutilizable
- mezcla responsabilidades
✅ Bien (Page devuelve estado, Test valida)
Page
public String obtenerTitulo() {
return wait.until(
ExpectedConditions.visibilityOfElementLocated(dashboardHeader)
).getText();
}Test
check.equals(
dashboard.obtenerTitulo(),
"Tablero",
"Título del dashboard"
);La Page:
- obtiene información
El Test: - decide si es correcta
Por qué esta separación importa (mucho)
Esta división permite que:
- la UI cambie sin romper todos los tests
- los tests sean más legibles
- las Pages sean reutilizables
- el framework escale
- el mantenimiento sea más barato
- los errores sean más fáciles de diagnosticar
Y, sobre todo:
El test lee como un caso de negocio, no como código Selenium.
Conclusión
El Page Object Model no es una moda ni una convención arbitraria.
Es una forma de controlar la complejidad cuando los tests crecen.
Separar Page y Test es lo que hace que un proyecto de Selenium:
- pase de “funciona”
- a “es mantenible”.
DashboardPage: validar navegación correcta
Así armé page del Dashboard:
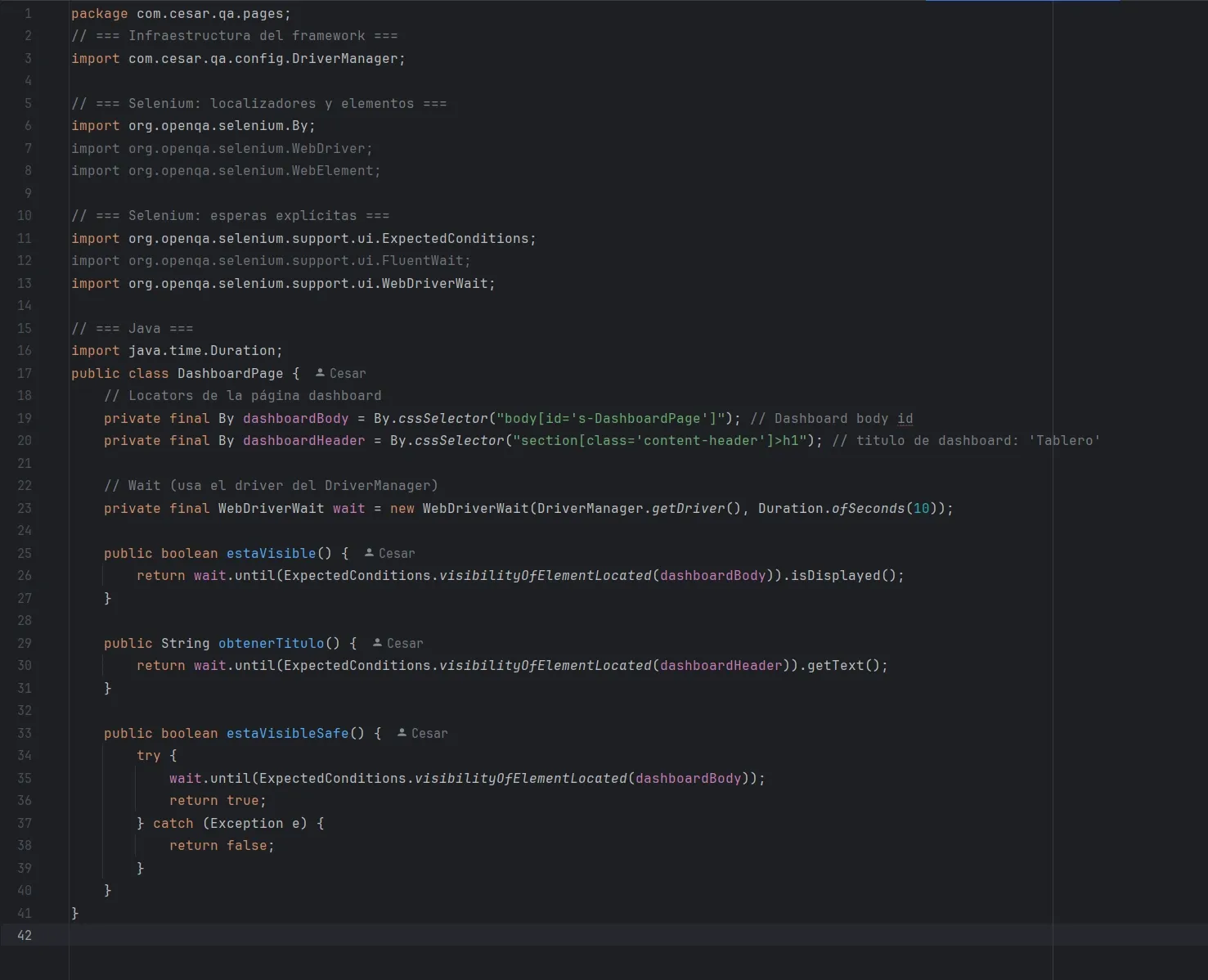
Esto permite:
- positivos →
estaVisible() - negativos →
estaVisibleSafe()
El rol de check.java: validaciones sin cortar la ejecución
En este lab decidí no usar assertions tradicionales (assert, AssertionError, TestNG, etc.) y crear una clase propia llamada check.
Esto no es casual ni “reinventar la rueda”: responde a un objetivo concreto del lab.
🎯 Objetivo del check
Quería que los tests:
- sigan ejecutándose aunque haya fallos
- muestren todos los errores en una sola corrida
- dejen un log legible, similar a TestComplete (
log.warning,log.error, checkpoints)
En otras palabras:
👉 prefiero visibilidad total del estado del sistema antes que cortar en el primer error.
Por qué no uso assert (por ahora)
En Java, y especialmente en frameworks como TestNG o JUnit:
- una
assertfallida
→ lanza una excepción
→ corta el test
→ y muchas veces corta el resto del flujo
Eso es correcto y deseable en muchos contextos (CI, pipelines, smoke tests).
Pero en este laboratorio inicial, no es lo que quiero.
Vengo de TestComplete, donde podía configurar:
- Stop on error
- Stop on warning
y normalmente los desactivaba para:
- ejecutar toda la batería
- ver todos los problemas juntos
- luego decidir qué corregir
check.java replica ese mismo enfoque, pero en Selenium puro.
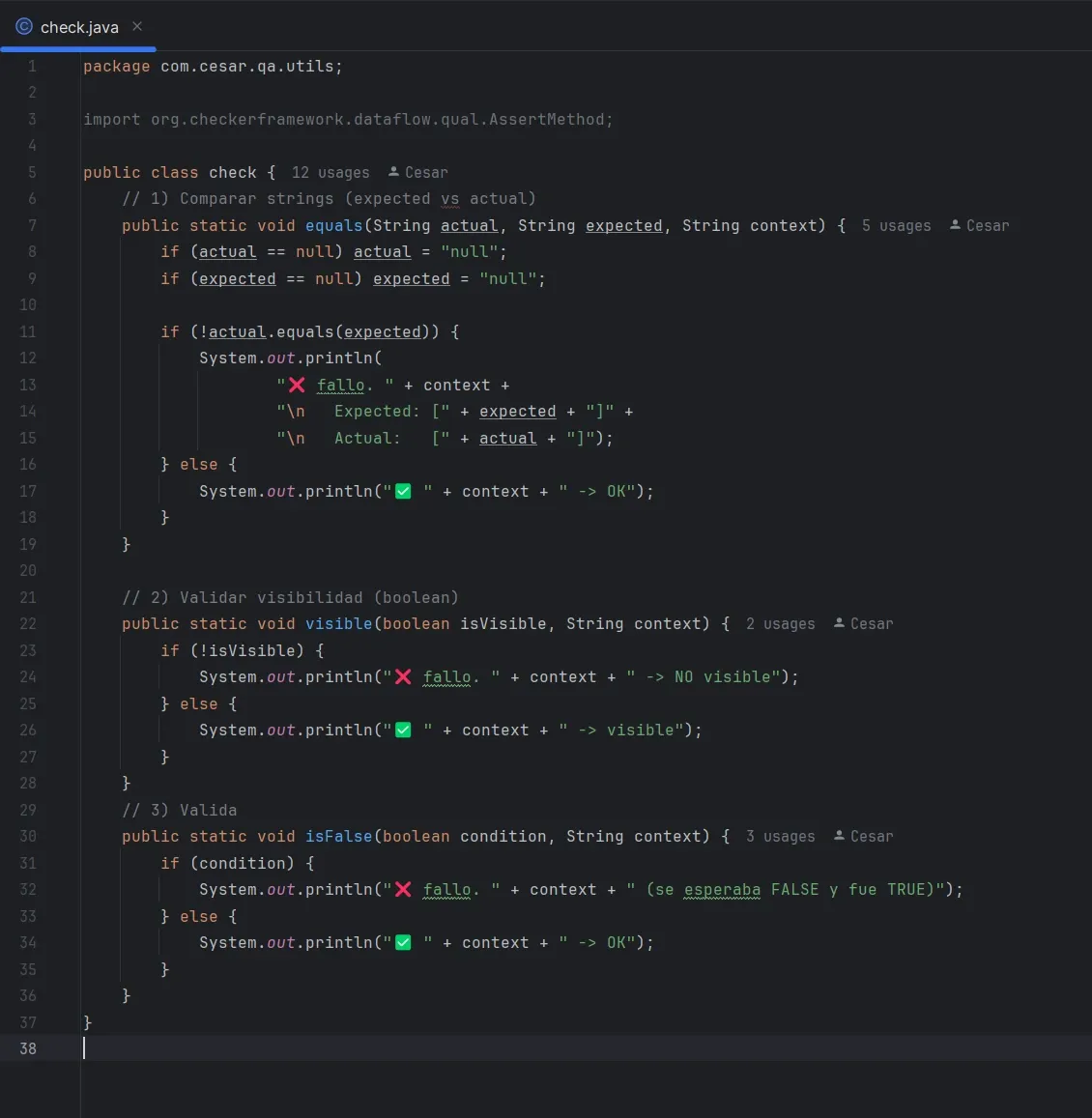
Qué es check.java
check es una clase utilitaria de validaciones.
No interactúa con la UI.
No conoce Selenium.
No conoce Pages.
Solo responde a una pregunta:
“¿Lo que esperaba ocurrió o no?”
Y lo informa por consola de forma clara.
Estructura general
public class check {
// comparaciones de valores
// validaciones booleanas
// validaciones negativas (isFalse)
}Es stateless, todo es static, y puede ser llamada desde:
- tests
- pages (si se quisiera, aunque yo la uso desde tests)
1️⃣ Comparar valores: equals(actual, expected, context)
check.equals(
dashboard.obtenerTitulo(),
"Tablero",
"Título del dashboard"
);Qué hace
- compara
actualvsexpected - no lanza excepción
- imprime un resultado claro:
✔ OK si coincide
❌ FALLO si no coincide, mostrando ambos valores
Ejemplo de salida:
❌ fallo. Título del dashboard
Expected: [Tablero]
Actual: [Tablero principal]Esto es extremadamente útil cuando:
- validás textos
- montos
- estados visibles en pantalla
- valores formateados
2️⃣ Validar visibilidad: visible(boolean, context)
check.visible(
dashboard.estaVisible(),
"Dashboard visible luego de login válido"
);Importante
La lógica de cómo se obtiene la visibilidad no está acá.
Eso vive en la Page:
public boolean estaVisible() {
return wait
.until(ExpectedConditions.visibilityOfElementLocated(...))
.isDisplayed();
}check solo informa el resultado.
Esto refuerza una idea central del POM:
la Page obtiene estados
el Test decide qué validar
check solo reporta
3️⃣ Validación negativa: isFalse(condition, context)
Este método aparece cuando queremos expresar algo muy común en tests negativos:
“esto NO debería pasar”
Ejemplo:
check.isFalse(
dashboard.estaVisibleSafe(),
"El dashboard NO debería aparecer"
);Qué valida realmente
- si la condición es
true→ ❌ fallo - si la condición es
false→ ✔ OK
Y el mensaje lo deja explícito:
❌ fallo. El dashboard NO debería aparecer (se esperaba FALSE y fue TRUE)Esto es mucho más semántico y legible que escribir:
if (dashboard.estaVisible()) {
...
}Por qué esto no rompe el POM
check.java:
- no sabe nada del DOM
- no tiene
By - no usa
WebDriver - no tiene esperas
Solo consume valores ya calculados.
Por eso:
- no contamina las Pages
- no mezcla responsabilidades
- no acopla el test a Selenium
¿Esto es definitivo?
No.
Esto es intencionalmente transitorio.
Más adelante, al incorporar TestNG, este check puede:
- mapearse a soft asserts (
SoftAssert) - integrarse con reportes (Allure / Extent)
- o directamente reemplazarse
Pero como primer paso, cumple algo fundamental:
me permite pensar en estructura, flujo y diseño,
sin que el framework me tape los errores.
Idea clave de esta sección
check.java no existe para reemplazar TestNG.
Existe para entender qué estoy validando y por qué.
Y eso, en un lab de aprendizaje, vale muchísimo más que correr rápido.
Los tests: donde vive la intención
Tests positivos: validar que SI pase algo
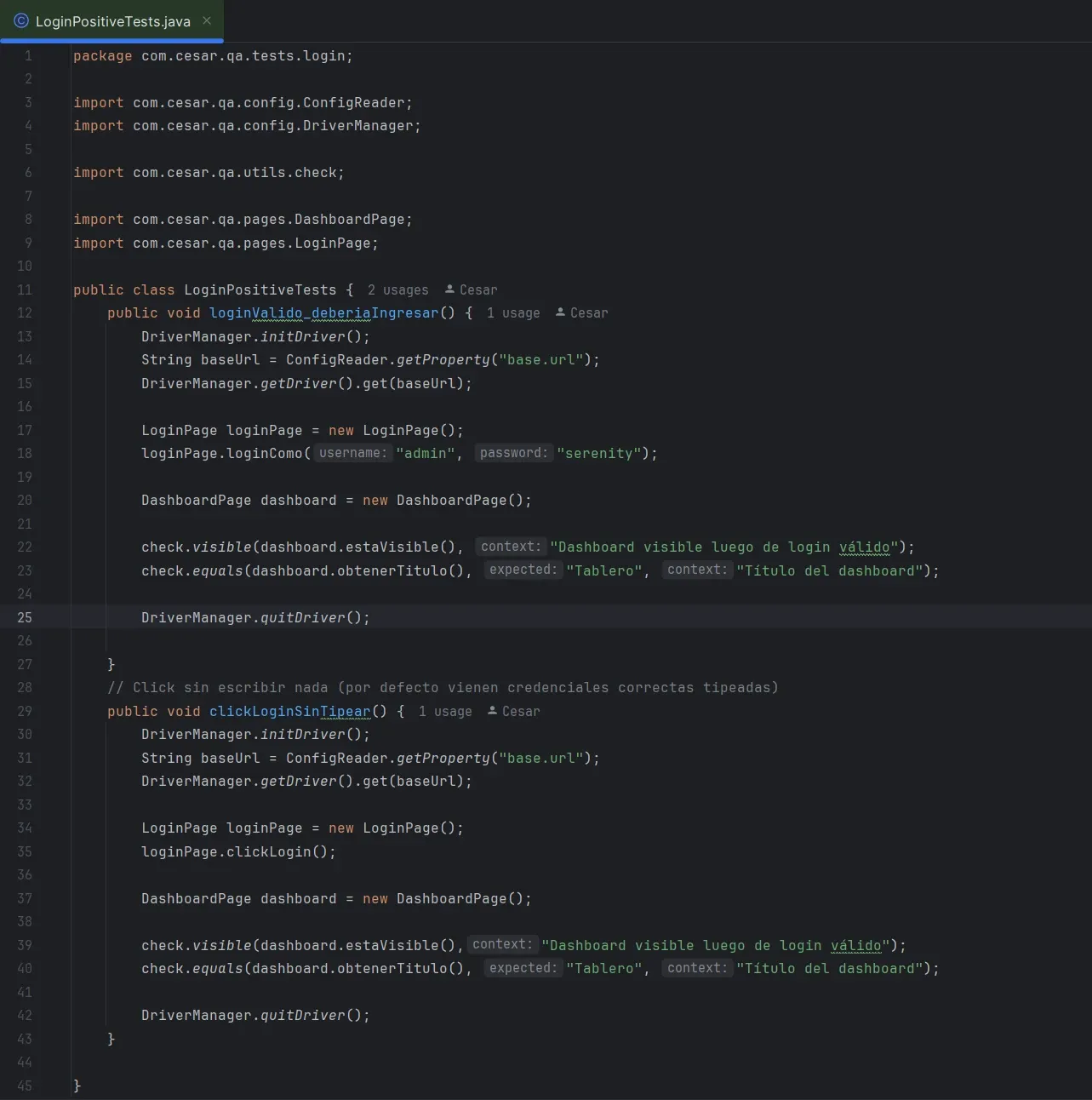
Tests negativos: validar que NO pase algo
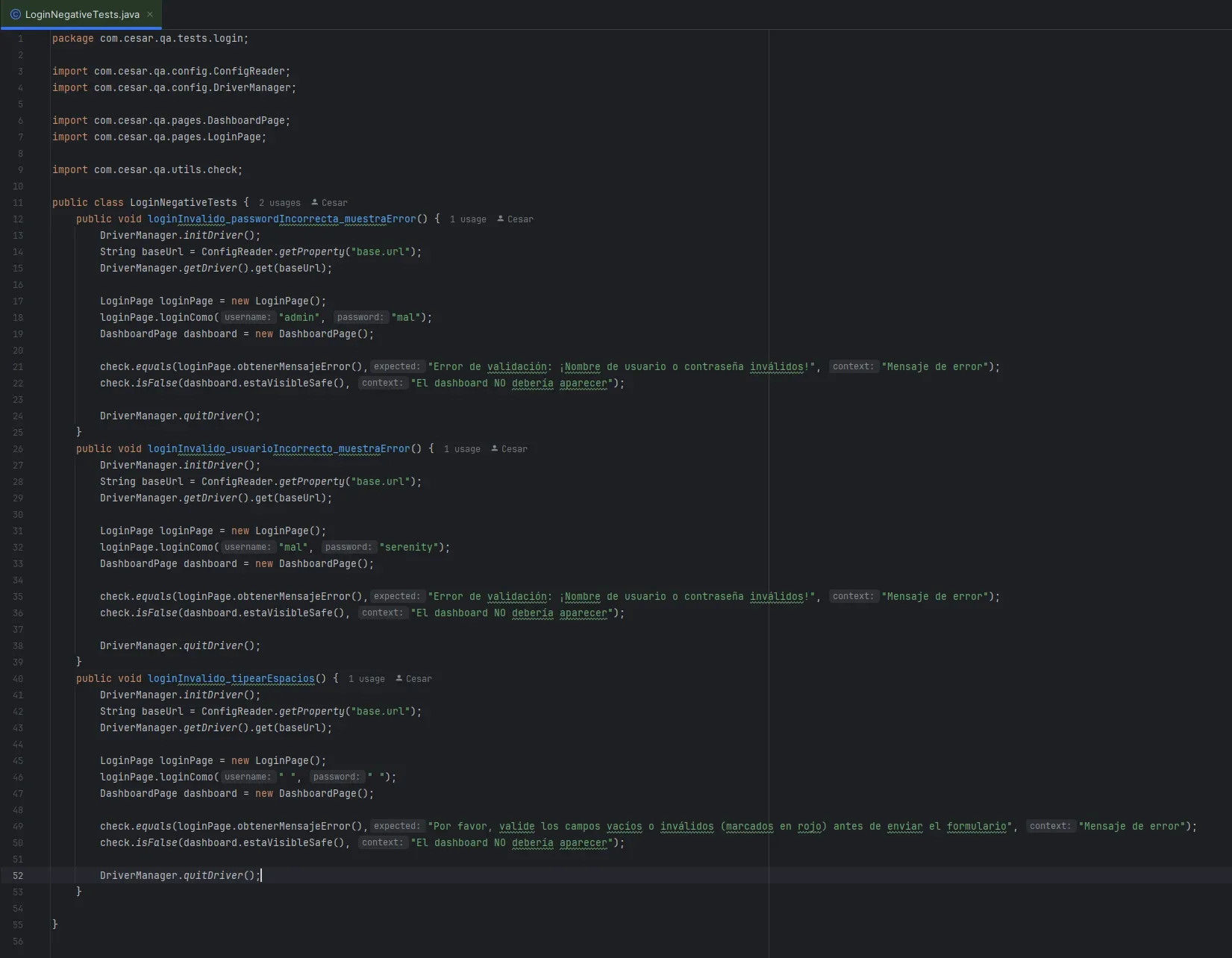
Estos tests:
- no saben qué selector tiene el dashboard
- no usan
By - no usan
WebElement - se leen como una historia de negocio
Por qué cada test abre el browser y lo cierra
En este punto del laboratorio decidí que cada test haga esto:
initDriver()get(baseUrl)- ejecutar acciones + validaciones
quitDriver()
Por qué elegí esto (y por qué está bien)
Porque me garantiza aislamiento total.
Cada test empieza desde cero, sin depender de lo que haya hecho el test anterior.
Eso trae ventajas concretas:
- Tests más confiables: si uno deja algo “raro” (sesión, cookies, estado del UI), no ensucia al siguiente.
- Menos debugging raro: cuando un test falla, sabés que falla por lo que hace ese test, no por residuos de otro.
- Más parecido a CI: en pipelines suele ejecutarse con entornos limpios o lo más limpios posible.
- Más fácil de paralelizar en el futuro: si cada test es independiente, después TestNG puede correrlos en paralelo.
📌 En resumen: prefiero pagar el costo de abrir Chrome varias veces a cambio de estabilidad y repetibilidad.
La alternativa: abrir una vez y correr todo “en serie” (una sola sesión)
También probé el otro enfoque:
- abrir el browser una sola vez
- ejecutar todos los tests
- cerrar al final
Eso puede servir si:
- estás explorando rápido
- querés velocidad en una demo
- estás haciendo un “happy path” largo como si fuera un flujo e2e
Pero tiene un costo:
- tests acoplados: el test 2 depende de que el test 1 deje todo bien
- estado compartido (cookies, UI, sesión, datos), que genera flakiness
- si algo se rompe a mitad de camino, perdés la corrida completa
👉 Para un suite real, esto termina siendo “un test gigante” disfrazado de muchos tests.
Entonces… ¿qué es “mejor”?
Depende del objetivo, pero como regla general:
✅ Para suites de regresión y automatización mantenible:
cada test independiente, browser limpio.
✅ Para un flujo e2e puntual (tipo smoke/happy path):
puede tener sentido mantener una sola sesión, pero incluso ahí muchos equipos prefieren independencia.
Conclusión
Lo importante es esto:
- La Page no abre ni cierra nada.
- La Page solo interactúa con UI.
- El Test controla el flujo (setup → acciones → checks → teardown).
Eso mantiene responsabilidades separadas y hace que el POM sea reutilizable.
El runner: ejecución en serie y control total
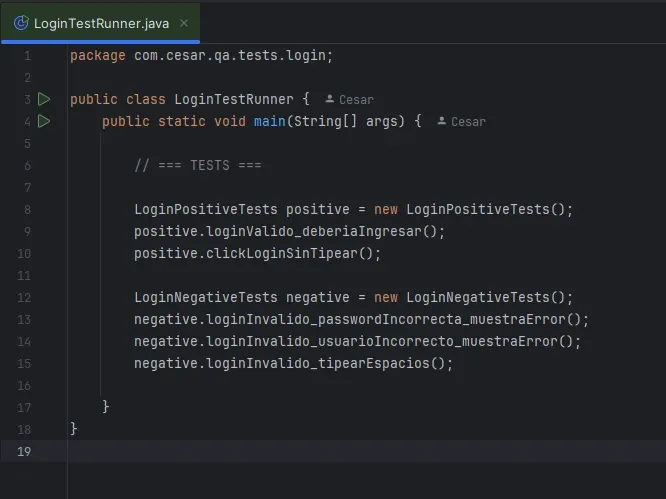
Este runner:
- ejecuta en orden
- permite ver todo el log
- no corta al primer error
Diagrama: “ruta del código” al debuggear (IntelliJ)
Esto es lo que seguirías con Step Into / Step Over:
LoginTestRunner.main()
|
|-- new LoginPositiveTests()
| |
| |-- loginValido_deberiaIngresar()
| |
| |-- DriverManager.initDriver()
| |-- baseUrl = ConfigReader.getProperty("base.url")
| |-- DriverManager.getDriver().get(baseUrl)
| |
| |-- new LoginPage()
| | |
| | |-- loginComo("admin","serenity")
| | |
| | |-- enterUsername()
| | |-- enterPassword()
| | |-- clickLogin()
| |
| |-- new DashboardPage()
| | |
| | |-- estaVisible()
| | |-- obtenerTitulo()
| |
| |-- check.visible(...)
| |-- check.equals(...)
| |
| |-- DriverManager.quitDriver()
|
|-- new LoginNegativeTests()
|
|-- loginInvalido_passwordIncorrecta_muestraError()
|
|-- initDriver() -> get(baseUrl)
|-- LoginPage.loginComo("admin","mal")
|-- check.equals(LoginPage.obtenerMensajeError(), expected)
|-- DashboardPage.estaVisibleSafe()
|-- check.isFalse(...)
|-- quitDriver()
etc.Correr los tests con POM
Al ejecutar LoginTestRunner el log es:
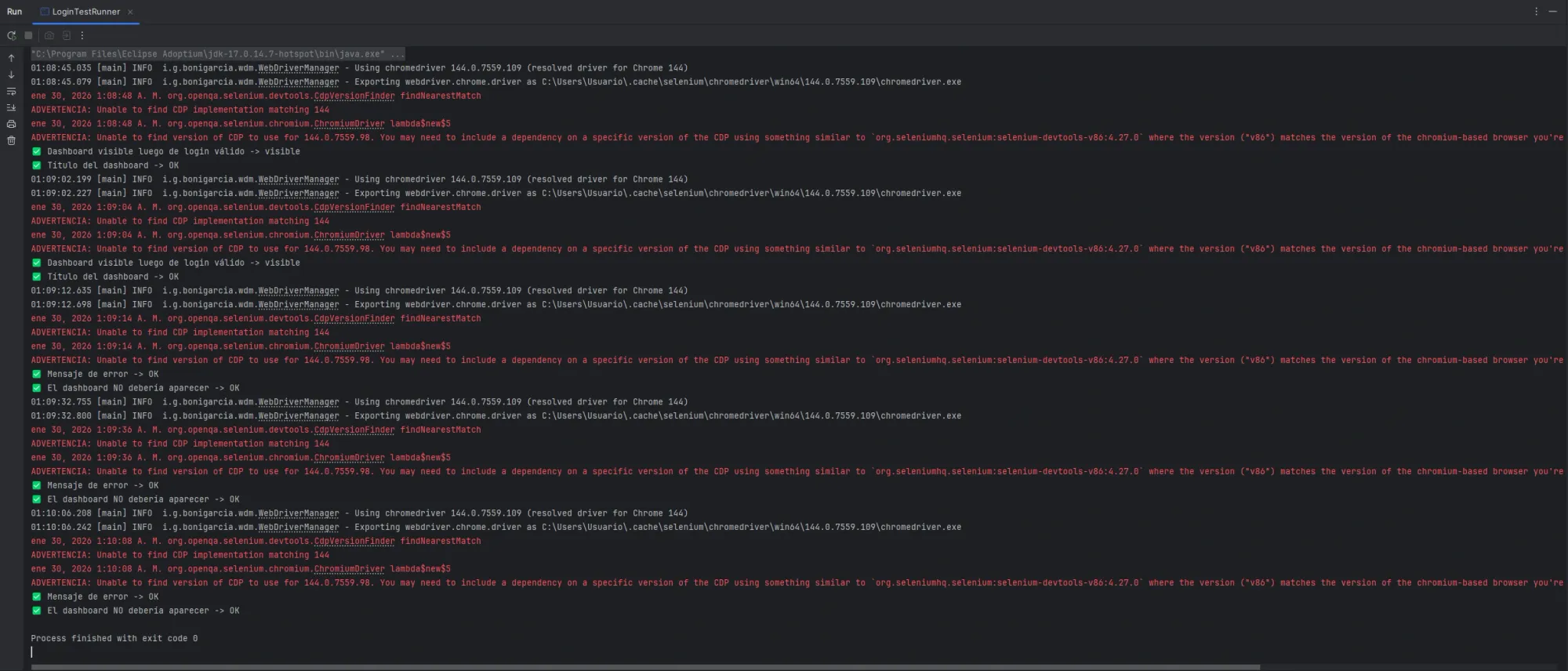
Aquí se vé:
1️⃣ Ejecución en serie, controlada por el runner
Cada bloque de logs corresponde a un test independiente, pero ejecutado en orden:
Login válido → dashboard visible
Login inválido → mensaje de error
Login inválido → dashboard NO apareceNo hay magia:
- el
LoginTestRunnerdecide el orden - cada test abre y cierra su propio driver
- el flujo es 100% predecible
📌 Esto es clave cuando todavía no usás TestNG/JUnit:
sabés exactamente qué se ejecuta y cuándo.
2️⃣ El driver se crea y destruye correctamente
Se repite este patrón varias veces:
Using chromedriver 144...
Exporting webdriver...Eso indica que:
- cada test arranca con un navegador limpio
- no hay estado compartido entre tests
- si un test falla, no contamina al siguiente
💡 Esto es buena práctica incluso cuando después migre a TestNG.
3️⃣ Warnings en rojo ≠ tests fallando
En la consola aparecen mensajes en rojo como:
WARNING: Unable to find CDP implementation matching 144Esto NO es un fallo del test.
Qué significa:
- Selenium intenta engancharse al Chrome DevTools Protocol
- no encuentra una versión exacta
- muestra el warning
- continúa normalmente
Prueba de eso:
- los tests siguen
- los checks dan OK
- el proceso termina con
exit code 0
📌 Importante para lectores junior:
no todo lo rojo en consola es un error funcional.
4️⃣ Validaciones legibles (gracias a check.java)
Las líneas importantes son estas:
✔ Dashboard visible luego de login válido -> visible
✔ Título del dashboard -> OK
✔ Mensaje de error -> OK
✔ El dashboard NO debería aparecer -> OKEsto muestra algo clave del enfoque:
- los tests no se cortan al primer error
- cada validación deja una evidencia clara
- el log se puede leer como una historia
Muy parecido a:
- TestComplete logs
- Allure steps
- o un reporte manual bien hecho
5️⃣ Separación clara entre infraestructura y negocio
En el log se distinguen capas:
- infraestructura
(WebDriverManager, Chrome, CDP warnings) - lógica de negocio del test
(Dashboard visible,Mensaje de error)
Eso es consecuencia directa del POM:
- la Page se encarga del “cómo”
- el Test expresa el “qué debería pasar”
6️⃣ El proceso termina limpio
El final:
Process finished with exit code 0Significa:
- no hubo excepciones no controladas
- el runner terminó su flujo
- el sistema quedó estable
📌 Esto es importante si mañana:
- corrés esto en CI
- lo integrás con reportes
- lo ejecutás en headless: Ejecutar en headless (sin cabeza) en testing significa automatizar pruebas web utilizando un navegador (como Chrome o Firefox) sin renderizar su interfaz gráfica de usuario (GUI). Las pruebas corren en segundo plano, lo que las hace más rápidas y eficientes al no consumir recursos gráficos, ideales para entornos de integración continua.
Esta salida de ejecución confirma que el Page Object Model no es solo una cuestión de ordenar clases.
Es una forma de construir un sistema de pruebas predecible, legible y controlable.
Cada test arranca desde cero, ejecuta su flujo, valida lo esperado y deja evidencia clara en el log.
Incluso ante warnings de Selenium, el framework se mantiene estable y continúa la ejecución.
A partir de esta base, el siguiente paso natural será integrar un runner formal (TestNG) y reportes (Allure), pero la arquitectura ya está preparada para eso.
Qué NO es POM (y errores comunes)
❌ Poner asserts dentro de la Page
❌ Usar driver.findElement en los tests
❌ Mezclar lógica de negocio con selectores
❌ Validar textos “hardcodeados” en múltiples tests
❌ Pages gigantes con lógica condicional compleja
Qué sigue después de esto
Este POM ya es válido y sano.
Los próximos pasos naturales son:
- Reemplazar el runner por TestNG
- Mover
initDriver / quitDrivera@BeforeMethod / @AfterMethod - Reemplazar
check.javapor asserts + listeners - Agregar reportes (Allure)
- Screenshots automáticos en fallo
- Agregar más tests y validaciones, talvez agregar otra page para realizar más pruebas.
Pero conceptualmente, el POM ya está hecho.
🔗 Todo el código de esta serie está en: github.com/cesarbeassuarez/qa-automation-lab
📂 selenium-java
—
Temas conectados:
Sesión 5 de este lab y Sesión 6 de este lab de Selenium con java.