Validar grilla web contra Excel con Selenium + Apache POI
SlickGrid, virtual scrolling, Apache POI y DataProvider. 91 registros validados en 1 min con data-driven testing. Código y errores reales.
Contexto: qué quería hacer
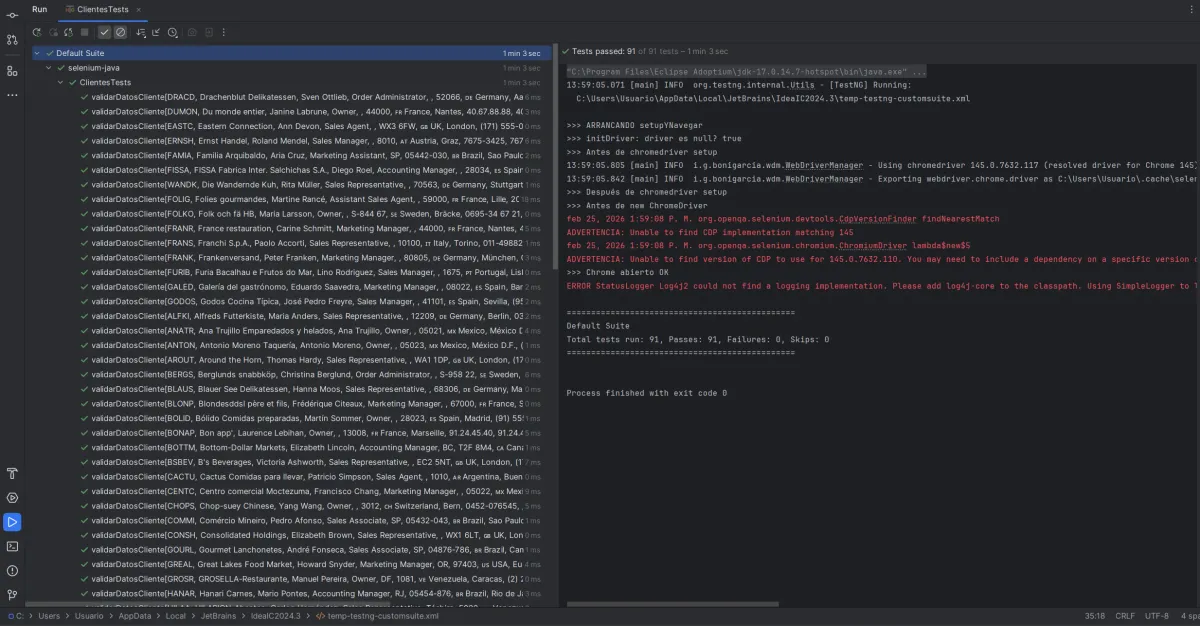
La app de prueba (StartSharp/Serenity) tiene una grilla de Clientes con 91 registros y 11 columnas: ID, Empresa, Contacto, Título, Región, Código Postal, País, Ciudad, Teléfono, Fax, Representantes.
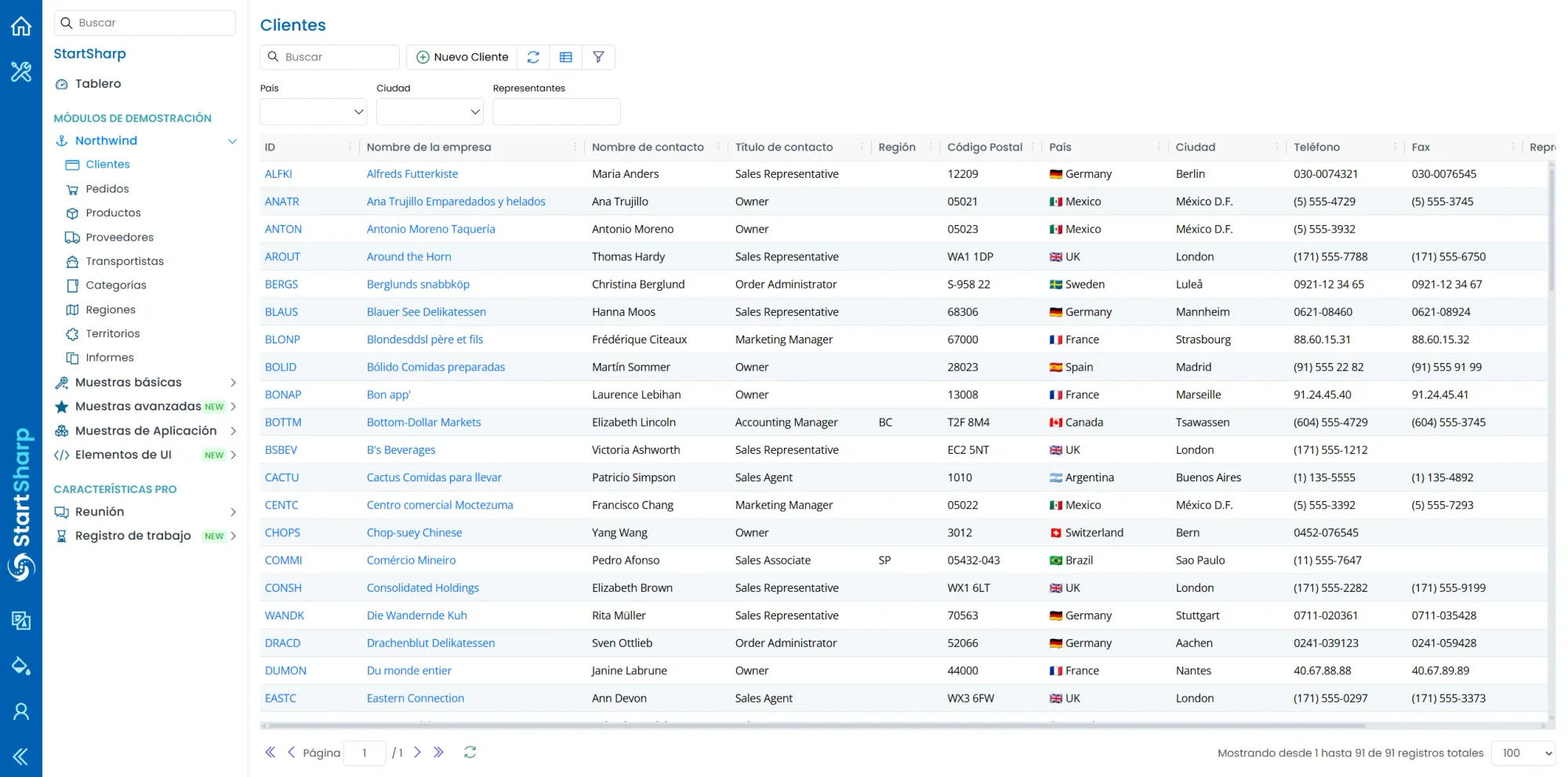
El objetivo: validar que cada celda de la grilla coincida con los datos esperados en un archivo Excel.
Parece simple. No lo fue.
El problema: virtual scrolling
La grilla usa SlickGrid. SlickGrid no renderiza las 91 filas en el DOM. Renderiza solo las que están visibles en pantalla — unas 15-20. Si scrolleás, destruye las filas de arriba y crea las de abajo.
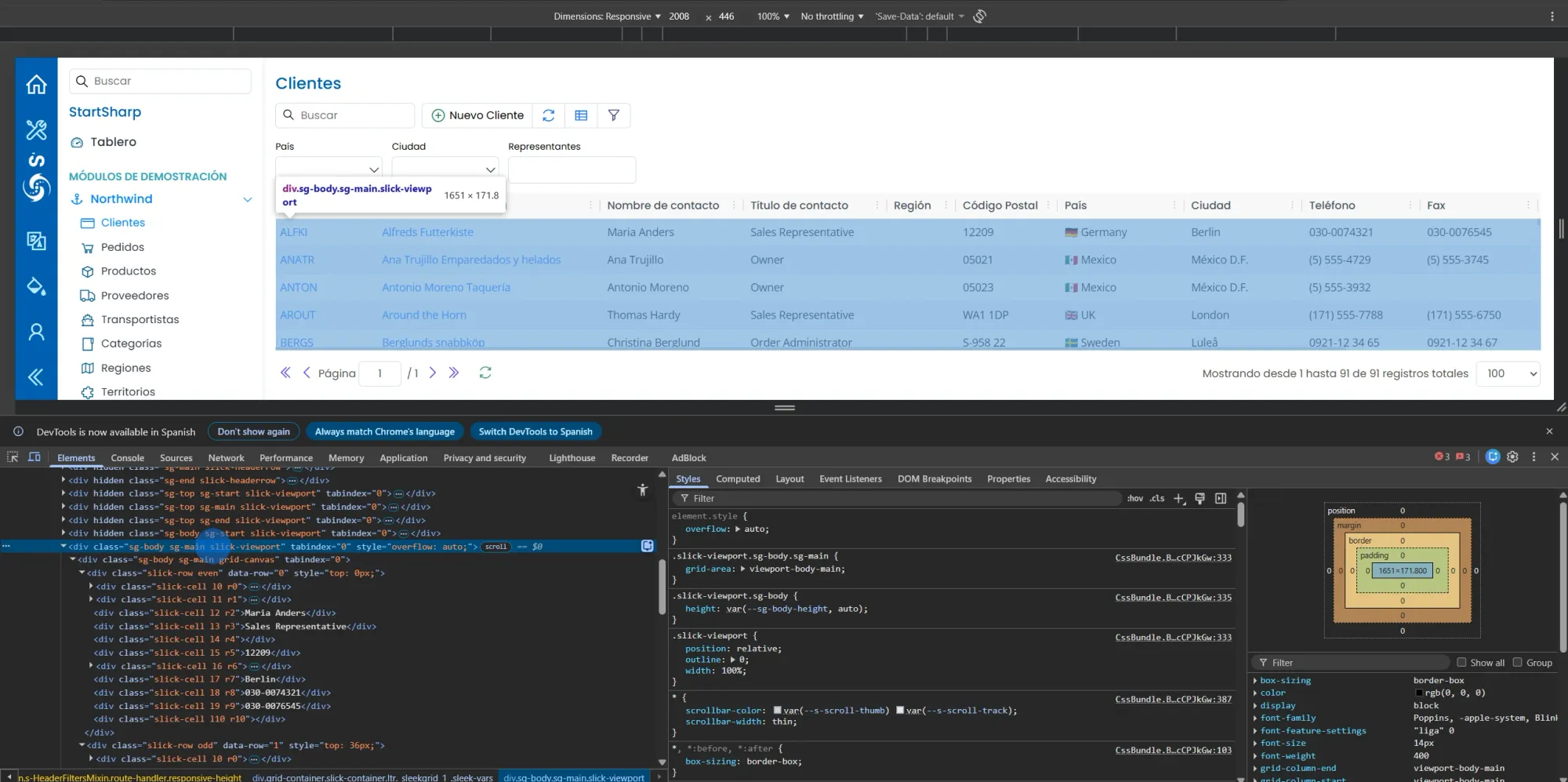
Esto significa que driver.findElements(By.cssSelector("div.slick-row")) solo devuelve las filas visibles. Las demás no existen.
Primer problema: ¿cómo extraigo los 91 registros para armar el Excel?
Extraer los datos: 4 intentos
Intento 1: querySelectorAll desde consola
document.querySelectorAll('div.slick-row')
Solo devolvió 15 filas. Las visibles. Obvio.
Intento 2: acceder al dataView de SlickGrid SlickGrid internamente tiene un objeto con todos los datos. Intenté accederlo desde la consola del browser. No funcionó — el widget de Serenity no lo expone.
Intento 3: scroll automático con JavaScript Armé un script que scrolleaba el viewport y capturaba filas. Funcionó parcialmente, pero los índices de las celdas no coincidían con las columnas reales. SlickGrid no renderiza las celdas en orden DOM — usa clases CSS como .slick-cell.l0, .slick-cell.l1, etc.
Intento 4 (el que funcionó): selectores por clase CSS + viewport gigante La solución fue usar DevTools en modo responsive (2000x9999px) para forzar el renderizado de todas las filas, y extraer con selectores específicos por clase:
let filas = document.querySelectorAll('div.slick-row');
let csv = 'ID\tEmpresa\tContacto\tTitulo\tRegion\tCodigoPostal\tPais\tCiudad\tTelefono\tFax\tRepresentantes\n';
filas.forEach(fila => {
let id = fila.querySelector('.slick-cell.l0')?.innerText.trim() || '';
let empresa = fila.querySelector('.slick-cell.l1')?.innerText.trim() || '';
let contacto = fila.querySelector('.slick-cell.l2')?.innerText.trim() || '';
let titulo = fila.querySelector('.slick-cell.l3')?.innerText.trim() || '';
let region = fila.querySelector('.slick-cell.l4')?.innerText.trim() || '';
let codigoPostal = fila.querySelector('.slick-cell.l5')?.innerText.trim() || '';
let pais = fila.querySelector('.slick-cell.l6')?.innerText.trim() || '';
let ciudad = fila.querySelector('.slick-cell.l7')?.innerText.trim() || '';
let telefono = fila.querySelector('.slick-cell.l8')?.innerText.trim() || '';
let fax = fila.querySelector('.slick-cell.l9')?.innerText.trim() || '';
let representantes = fila.querySelector('.slick-cell.l10')?.innerText.trim() || '';
csv += `${id}\t${empresa}\t${contacto}\t${titulo}\t${region}\t${codigoPostal}\t${pais}\t${ciudad}\t${telefono}\t${fax}\t${representantes}\n`;
});
copy(csv);
console.log('Copiado. Filas:', filas.length);El script de extracción: selectores por clase (.slick-cell.l0, .l1, etc.) en vez de índices de array. Esa fue la clave.
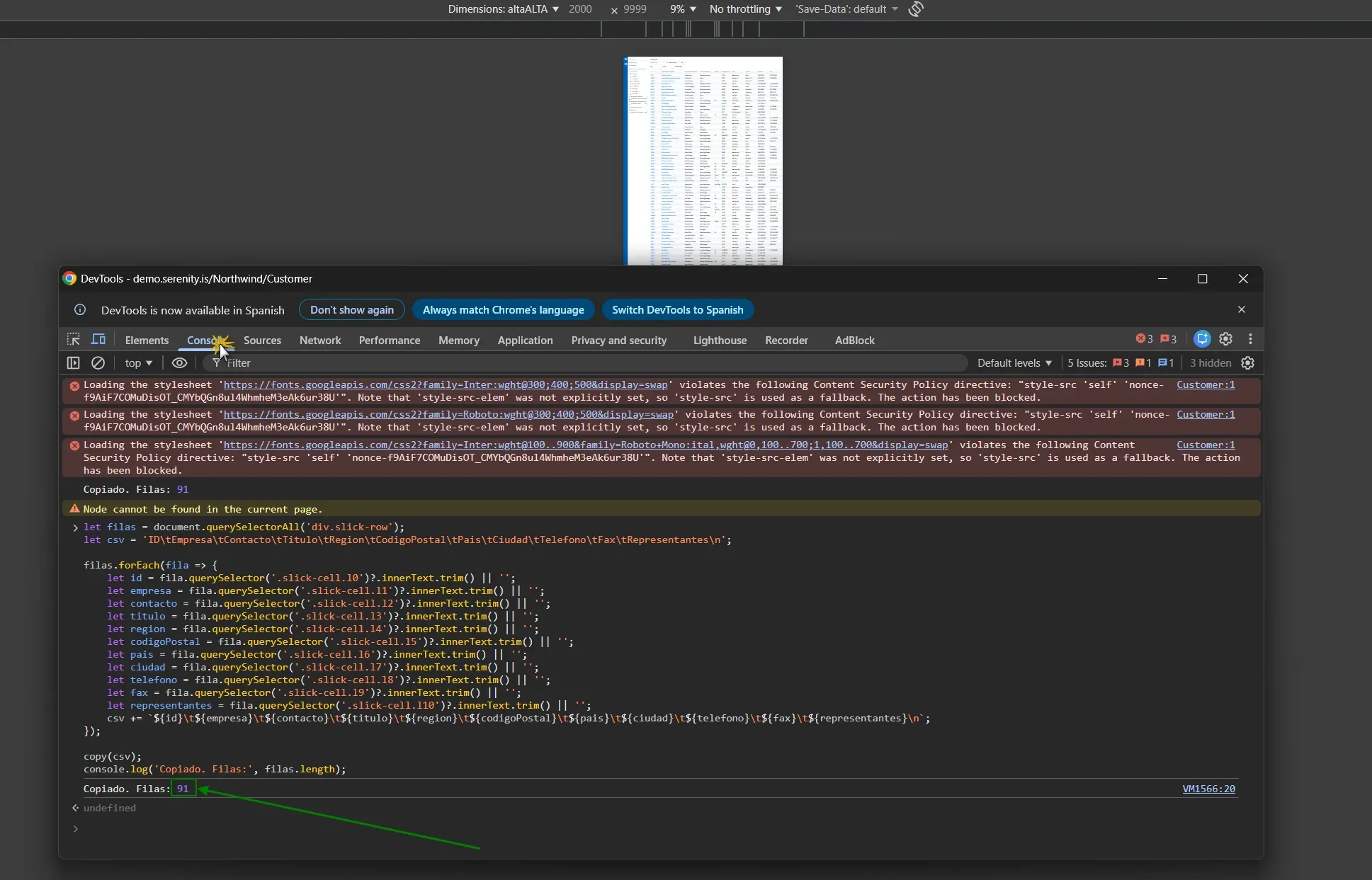
La clave: usar .querySelector('.slick-cell.l{N}') en vez de índices de array. Porque SlickGrid no garantiza orden DOM de las celdas.
Con eso copié las 91 filas al portapapeles, las pegué en Excel y tenía mi archivo de datos.
Estructura del código
Creé 4 archivos nuevos para esta sesión:
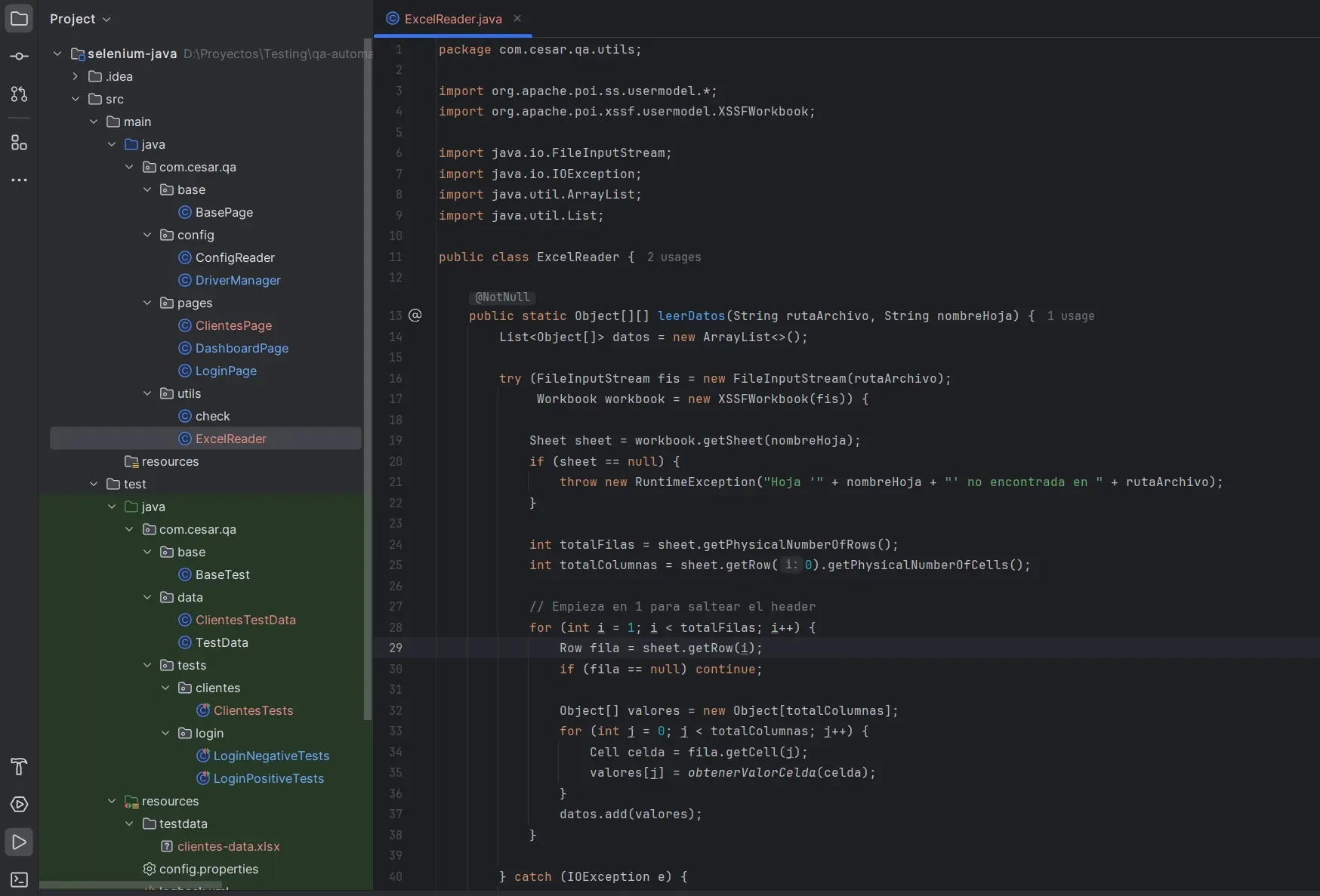
ExcelReader.java — utilidad para leer archivos .xlsx Usa Apache POI. Lee una hoja por nombre, saltea el header, devuelve Object[][] listo para DataProvider de TestNG.
public static Object[][] leerDatos(String rutaArchivo, String nombreHoja) {
FileInputStream archivo = new FileInputStream(rutaArchivo);
Workbook workbook = new XSSFWorkbook(archivo);
Sheet hoja = workbook.getSheet(nombreHoja);
// Saltear header (fila 0), leer resto
int filas = hoja.getLastRowNum();
int columnas = hoja.getRow(0).getLastCellNum();
Object[][] datos = new Object[filas][columnas];
// ... lectura celda por celda
return datos;
}
ClientesTestData.java — DataProvider que lee el Excel
@DataProvider(name = "datosClientes")
public static Object[][] datosClientes() {
return ExcelReader.leerDatos(
"src/test/resources/testdata/clientes-data.xlsx", "Clientes");
}
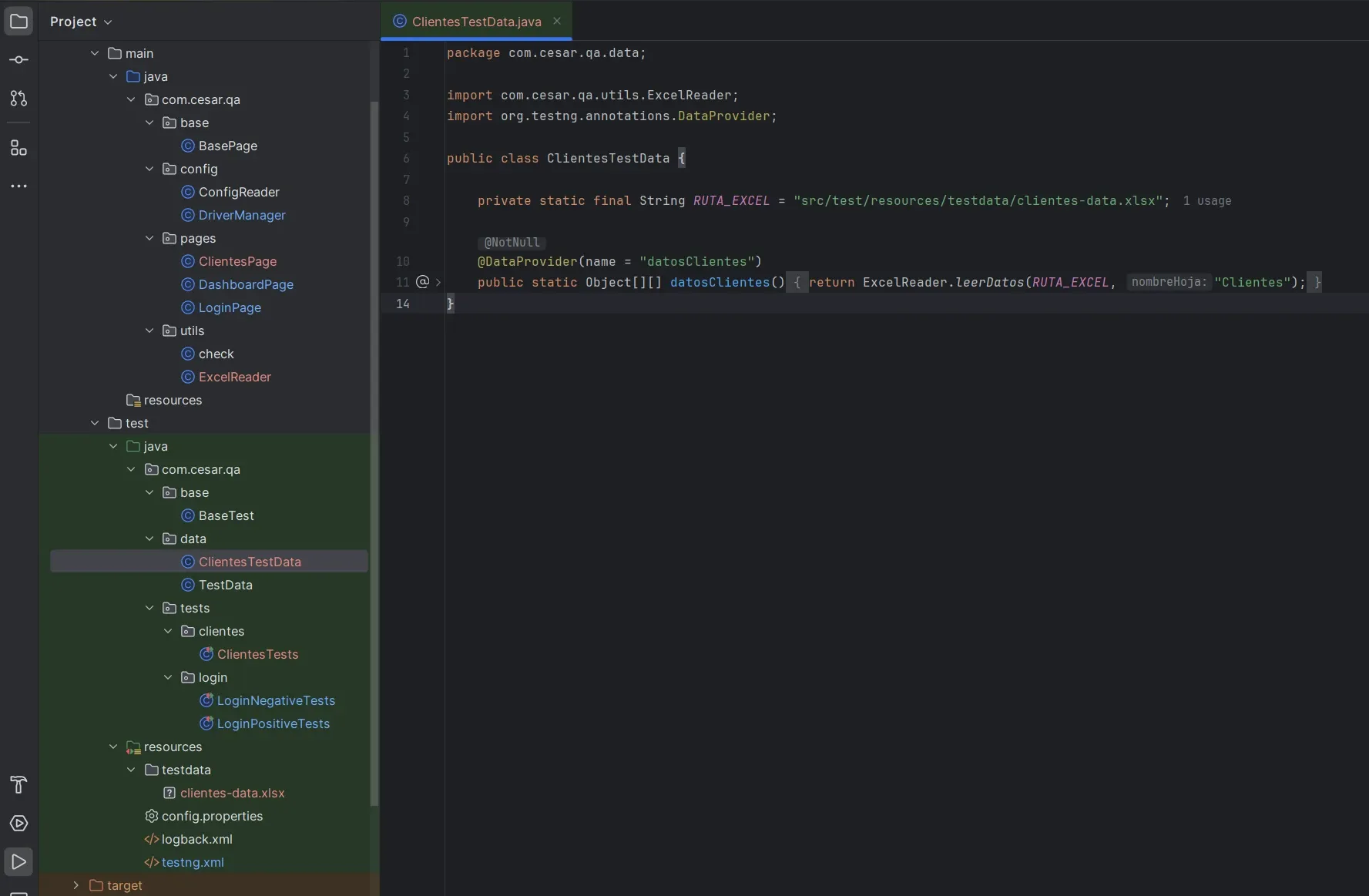
Lo separé de TestData.java (que tiene los DataProviders con arrays hardcodeados) porque la lógica es distinta: este lee desde archivo.
ClientesPage.java — Page Object para la grilla Acá está toda la lógica de interacción con SlickGrid. Los locators, las constantes de columnas, y los métodos de lectura.
ClientesTests.java — los tests No extiende BaseTest (explico por qué más abajo). Usa @BeforeClass / @AfterClass.
Dependencia nueva: Apache POI
Agregué en el pom.xml:
<poi.version>5.2.5</poi.version>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
Apache POI es la librería estándar en Java para leer/escribir archivos Excel. Para automation con DataProviders desde Excel, es lo que se usa.
El primer locator que falló
Implementé ClientesPage con este locator para el canvas de la grilla:
private final By grillaCanvas = By.cssSelector("div.grid-canvas");
Primer run:
TimeoutException: waiting for visibility of element located by
By.cssSelector: div.grid-canvas (tried for 10 second(s))
El selector existía, pero SlickGrid tiene múltiples contenedores con esa clase. El correcto era más específico:
private final By grillaCanvas = By.cssSelector("div.sg-body.sg-main.grid-canvas");
Para encontrarlo, abrí DevTools, busqué el contenedor de las filas visibles, y copié la combinación de clases completa.
Lección: en grillas complejas como SlickGrid, un selector genérico no alcanza. Hay que inspeccionar bien la estructura del DOM.
La navegación: por menú, no por URL
Originalmente navegaba a Clientes con URL directa:
DriverManager.getDriver()
.get(ConfigReader.getProperty("base.url") + "/#Demo-Northwind-Customer");
No funcionó. La página no cargaba la grilla correctamente con navegación directa.
La solución fue navegar como un usuario real: click en Northwind → click en Clientes.
Agregué un método en DashboardPage:
private final By btnNorthwind = By.cssSelector("a[href='#nav_menu1_2_1']");
private final By linkClientes = By.cssSelector("ul[data-bs-parent='#nav_menu1_2'] li:first-child a");
public void irAClientes() {
wait.until(ExpectedConditions.elementToBeClickable(btnNorthwind)).click();
wait.until(ExpectedConditions.elementToBeClickable(linkClientes)).click();
}
Y en ClientesTests el test no importa DriverManager ni ConfigReader. El test solo habla con Pages. Eso es parte del patrón: los tests no deberían saber cómo funciona el driver internamente.
El error de los 18 minutos
Primer run completo: 91 tests, 18 minutos.
¿Por qué? Porque cada iteración del DataProvider ejecutaba @BeforeMethod + @AfterMethod heredados de BaseTest: abrir Chrome → login → navegar → validar UNA fila → cerrar Chrome. 91 veces.
Primer intento: separé navegación en @BeforeMethod de ClientesTests. Pero TestNG ejecuta ambos @BeforeMethod (el de BaseTest y el de ClientesTests) antes de cada iteración. Mismo problema.
La solución: que ClientesTests no extienda BaseTest. Manejé el ciclo de vida del browser directamente:
public class ClientesTests { // sin extends BaseTest
private ClientesPage clientesPage;
@BeforeClass
public void setupYNavegar() {
DriverManager.initDriver();
// login, navegación, esperar grilla — UNA sola vez
}
@Test(dataProvider = "datosClientes", dataProviderClass = ClientesTestData.class)
public void validarDatosCliente(String id, String empresa, ...) {
// 91 iteraciones sobre la misma sesión
}
@AfterClass
public void tearDown() {
DriverManager.quitDriver();
}
}
@BeforeClass se ejecuta una vez antes de todos los tests. @AfterClass una vez al final. Las 91 iteraciones del DataProvider corren sobre la misma sesión de Chrome.
El problema del virtual scrolling (otra vez)
Con la nueva estructura, corrí de nuevo. Resultado: 70 failed, 21 passed.
RuntimeException: Cliente con ID 'FOLKO' no encontrado en la grilla
El mismo problema de virtual scrolling. El método obtenerValorPorId buscaba la fila en el DOM, pero FOLKO no estaba renderizada porque estaba fuera del viewport.
Primer intento: scrollear la grilla hasta encontrar cada fila. Funcionó, pero ahora cada validación scrolleaba toda la grilla. 91 filas × 10 columnas = 910 scrolls. Resultó en los 18 minutos otra vez.
La solución real: leer TODA la grilla una sola vez, guardar en memoria, y después consultar sin tocar el DOM.
// Map<ID, String[]> — una sola lectura
private Map<String, String[]> datosGrilla;
public void leerGrillaCompleta() {
datosGrilla = new HashMap<>();
JavascriptExecutor js = (JavascriptExecutor) driver;
WebElement vp = driver.findElement(viewport);
int alturaTotal = ((Number) js.executeScript(
"return arguments[0].scrollHeight", vp)).intValue();
int paso = ((Number) js.executeScript(
"return arguments[0].clientHeight", vp)).intValue();
// Scroll desde inicio hasta el final
js.executeScript("arguments[0].scrollTop = 0", vp);
pausa(300);
for (int pos = 0; pos <= alturaTotal; pos += paso / 2) {
js.executeScript("arguments[0].scrollTop = arguments[1]", vp, pos);
pausa(200);
List<WebElement> filasVisibles = driver.findElements(filas);
for (WebElement fila : filasVisibles) {
WebElement celdaId = fila.findElement(By.cssSelector("div.slick-cell.l0"));
String id = celdaId.getText().trim();
if (!id.isEmpty() && !datosGrilla.containsKey(id)) {
String[] valores = new String[TOTAL_COLUMNAS];
for (int col = 0; col < TOTAL_COLUMNAS; col++) {
try {
WebElement celda = fila.findElement(
By.cssSelector("div.slick-cell.l" + col));
valores[col] = celda.getText().trim();
} catch (Exception e) {
valores[col] = "";
}
}
datosGrilla.put(id, valores);
}
}
}
}
El truco: scrolleo con overlap (paso / 2) para no saltear filas entre renders. Cada fila leída se guarda en un HashMap con el ID como clave. Si ya la leí, la ignoro.
Después, consultar es instantáneo:
public String obtenerValorPorId(String clienteId, int indiceColumna) {
String[] fila = datosGrilla.get(clienteId);
return fila[indiceColumna];
}
Sin tocar el DOM. Sin scrollear. Lectura directa de memoria.
WebDriverManager colgado
Después de implementar todo esto, intenté correr y... no pasaba nada. Chrome no abría. IntelliJ se quedaba en "0 of 1 test" indefinidamente.
Agregué prints de diagnóstico en DriverManager:
System.out.println(">>> Antes de chromedriver setup");
WebDriverManager.chromedriver().setup();
System.out.println(">>> Después de chromedriver setup");
El último print que aparecía era "Antes de chromedriver setup". Se colgaba ahí.
WebDriverManager estaba intentando verificar/descargar chromedriver y algo en la red o en la caché lo trababa.
La solución: bypasear WebDriverManager y apuntar directo al chromedriver que ya tenía cacheado:
System.setProperty("webdriver.chrome.driver",
"C:\\Users\\Usuario\\.cache\\selenium\\chromedriver\\win64\\145.0.7632.117\\chromedriver.exe");
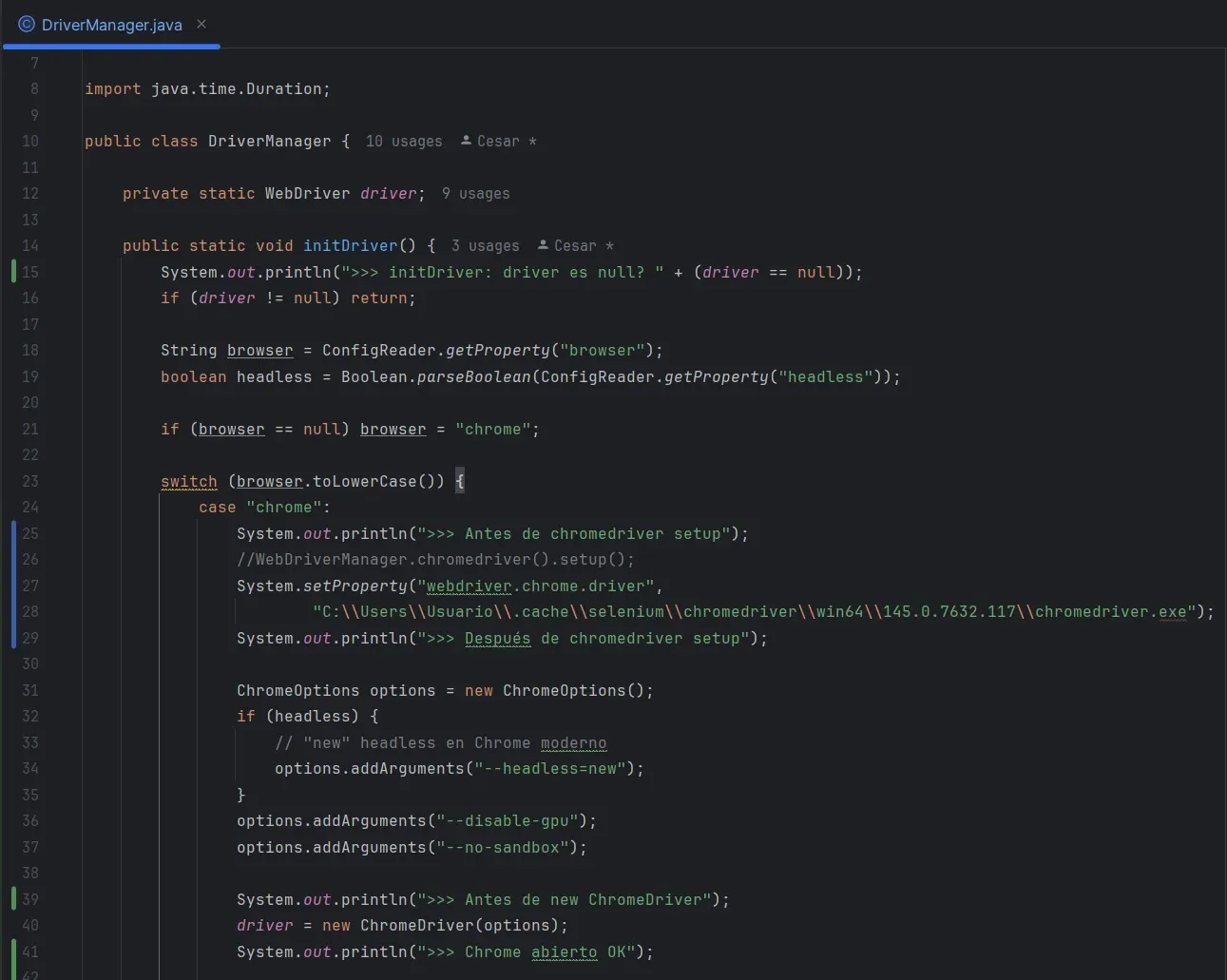
No es la solución ideal, pero desbloqueó el run. Después investigaré por qué WebDriverManager se colgaba.
Ahora ya anda Ok:
WebDriverManager.chromedriver().setup();Resultado final
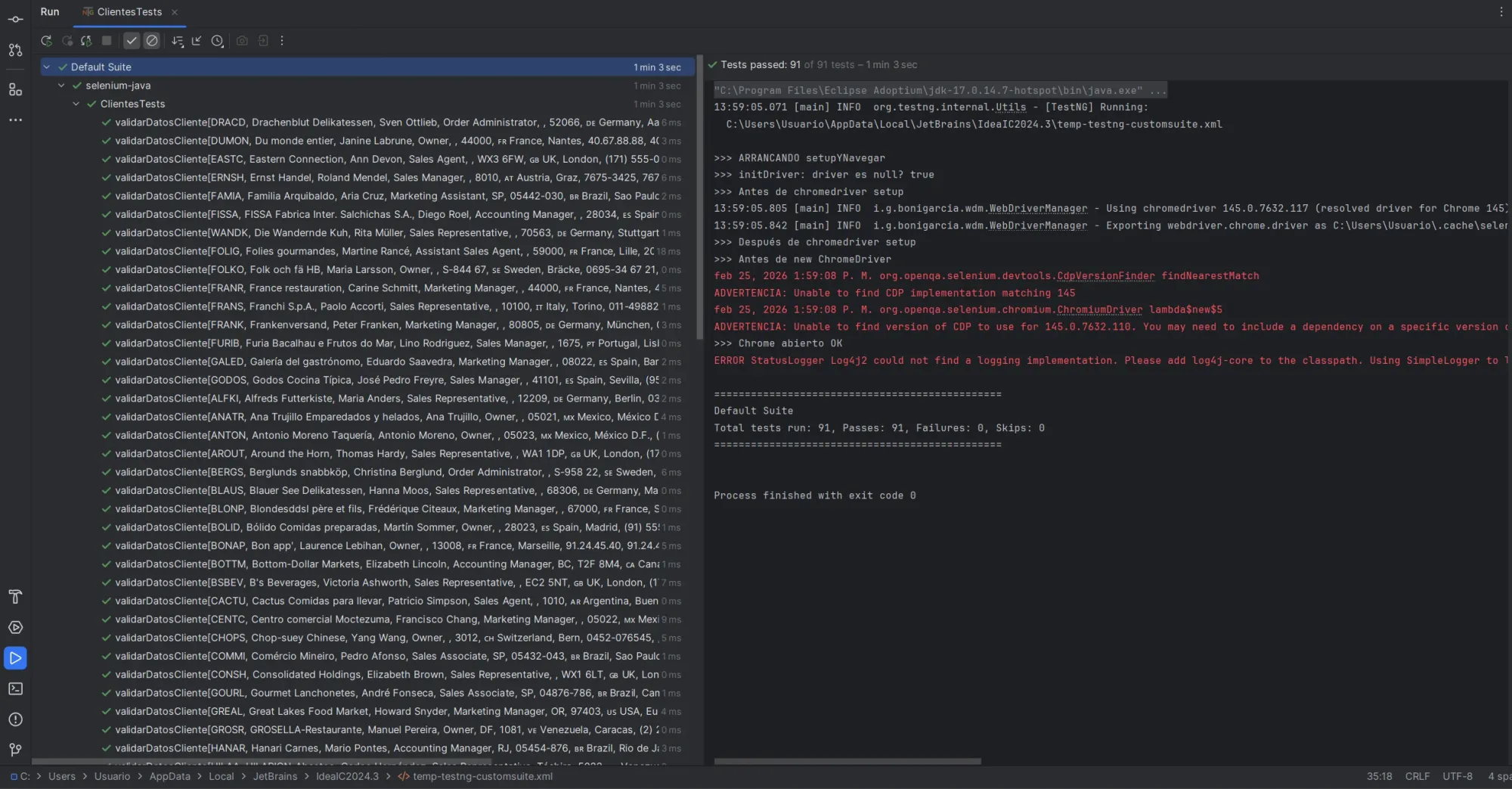
91 tests. 1 minuto 3 segundos. 83 passed, 8 failed.
Los 8 que fallaron fueron por datos, no por código:
- Códigos postales con ceros a la izquierda: Excel los interpreta como número y les saca el cero. La grilla dice "05033", el Excel dice "5033". Los arreglé tipeando '05033, agregando un ' antes de esos números.
- Algunos campos que deliberadamente dejé incorrectos en el Excel para ver cómo se reportan las diferencias.
El framework funciona. La lectura de grilla funciona. La validación contra Excel funciona.
De 18 minutos a 1 min — la diferencia entre scrollear 910 veces el DOM y leer una vez en memoria.
Limitaciones actuales
- Hoy comparamos filas/celdas, pero todavía no detectamos “filas extra” en la grilla vs Excel.
- Hoy no validamos el orden (asumimos que no importa / o no lo modelamos aún).
- Próximas mejoras: validar conteo y validar orden (o definir explícitamente orden no relevante y comparar por clave).
Roadmap en GitHub: Issue #1 (filas extra/missing) y Issue #2 (orden)
Lo que aprendí
SlickGrid no es una tabla HTML. No podés hacer findElements y esperar todas las filas. Virtual scrolling significa que el DOM es dinámico: filas aparecen y desaparecen según el scroll. Hay que trabajar con eso, no contra eso.
Leer una vez, consultar muchas. El patrón HashMap resolvió el problema de performance. En vez de 910 interacciones con el DOM, hice ~15 scrolls y 91 lecturas de memoria.
@BeforeClass vs @BeforeMethod. Con DataProviders de muchas filas, @BeforeMethod por iteración es un problema. @BeforeClass ejecuta el setup una vez y todas las iteraciones corren sobre la misma sesión.
WebDriverManager puede fallar. Tener un plan B (path directo al chromedriver) puede ahorrarte horas de debugging cuando el problema no es tu código sino la herramienta.
Los tests no deberían importar DriverManager. En este caso lo hice porque necesitaba @BeforeClass y BaseTest usa @BeforeMethod. Es un trade-off: gané performance pero perdí abstracción. La solución futura es refactorizar BaseTest para soportar ambos escenarios.
Estructura actual del proyecto
selenium-java/
├── src/
│ ├── main/java/com/cesar/qa/
│ │ ├── base/
│ │ │ └── BasePage.java
│ │ ├── config/
│ │ │ ├── ConfigReader.java
│ │ │ └── DriverManager.java
│ │ ├── pages/
│ │ │ ├── ClientesPage.java ← NUEVO
│ │ │ ├── DashboardPage.java (modificado: irAClientes)
│ │ │ └── LoginPage.java
│ │ └── utils/
│ │ ├── check/
│ │ └── ExcelReader.java ← NUEVO
│ └── test/
│ ├── java/com/cesar/qa/
│ │ ├── base/
│ │ │ └── BaseTest.java
│ │ ├── data/
│ │ │ ├── ClientesTestData.java ← NUEVO
│ │ │ └── TestData.java
│ │ └── tests/
│ │ ├── clientes/
│ │ │ └── ClientesTests.java ← NUEVO
│ │ └── login/
│ │ ├── LoginNegativeTests.java
│ │ └── LoginPositiveTests.java
│ └── resources/
│ ├── testdata/
│ │ └── clientes-data.xlsx ← NUEVO
│ ├── config.properties
│ ├── logback.xml
│ └── testng.xml
└── pom.xml (modificado: Apache POI)
Estado actual
Tengo:
- Lectura de grilla SlickGrid con manejo de virtual scrolling
- Validación de 91 registros × 11 columnas contra Excel
- DataProvider desde archivo .xlsx con Apache POI
- Navegación por menú (no por URL directa)
- 91/91 tests pasando
- Tiempo total: 1 minuto 3 segundos
Próximo paso
Allure Reports — reporting profesional — darle presentación profesional a estos resultados.
🔗 Todo el código de esta serie está en: github.com/cesarbeassuarez/qa-automation-lab
📂 selenium-java
—