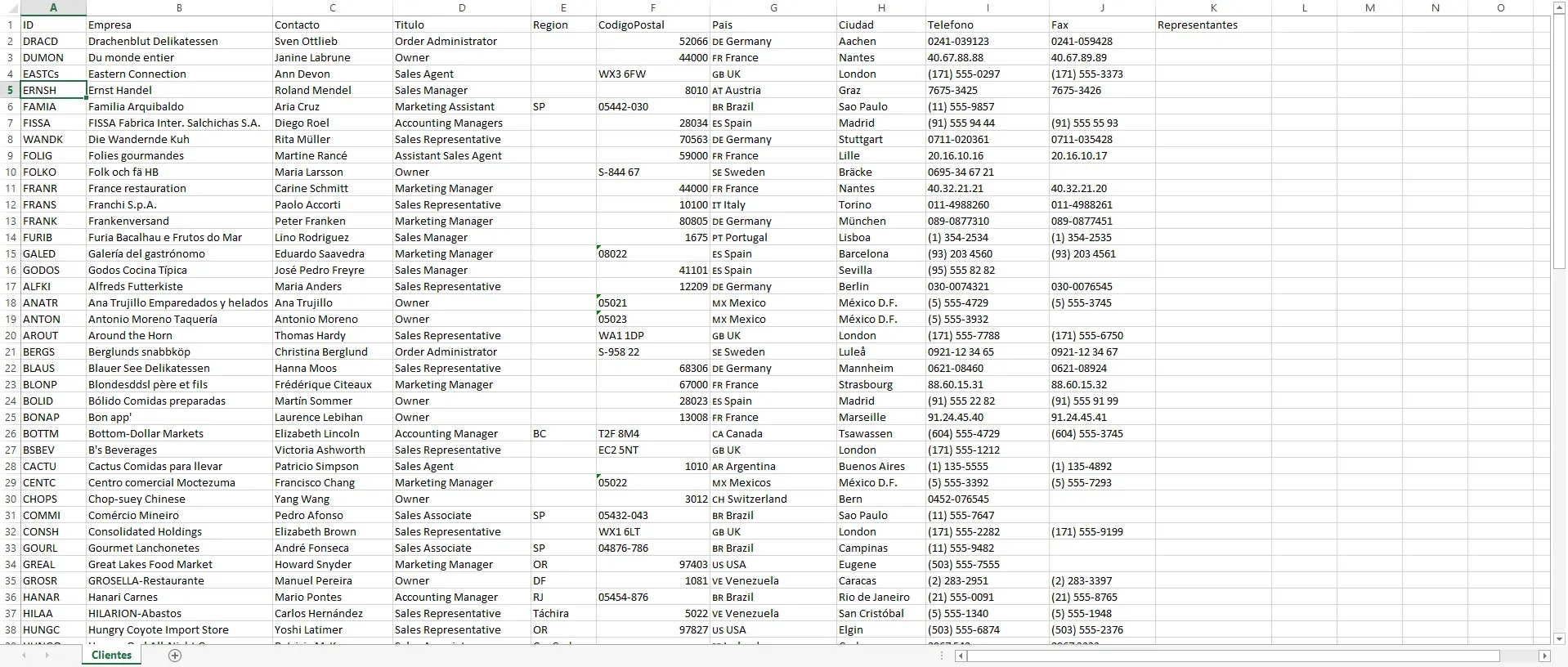
Validar 91 clientes contra Excel en Playwright: el bug que Selenium no había encontrado
exceljs, page.evaluate para grillas virtualizadas con SlickGrid, soft assertions para validar 910 comparaciones en un solo test.
Nota para el lector
Este post documenta cómo armé en Playwright el equivalente a mi ClientesTests de la serie de Selenium: leer un Excel con 91 clientes, leer la grilla web, y comparar campo a campo.
Si querés ir al grano:
- Solo ver el spec final y los bugs detectados → saltá a "El spec de comparación" y "Los errores que aparecieron".
- Ver el bug invisible que Selenium no encontró → saltá directo a "El cuarto error: WOLZA".
- Entender por qué validar 91 filas contra Excel suele ser mala idea → seguí en orden desde el principio.
La pregunta que abre este post
Antes de escribir una sola línea de código me hice esta pregunta:
En un caso real, ¿cómo se validan los datos de esta grilla? Son bastantes datos. ¿Con JSON? ¿Con Excel? ¿Se valida la grilla completa o no? ¿Qué es lo más profesional, lo más senior?
Y la respuesta honesta es: depende del contexto, y la mayoría de los tutoriales no te lo dicen.
En un proyecto de producción real, contra una app con datos que cambian todos los días, validar 91 filas de UI contra un Excel mantenido a mano es una mala idea. El día que alguien actualice un teléfono en la base, el Excel queda desactualizado, el test falla, y vos no fallaste por un bug — fallaste por data drift. Mantener eso es trabajo administrativo, no testing.
Para volumen de datos, lo correcto en producción es validar contra la API directamente. La UI no es el lugar para chequear que los 91 registros existen y están bien.
Pero acá no estoy en producción. Estoy en demo.serenity.is, una app de demo estática. Los 91 clientes del dataset Northwind no van a cambiar. El Excel de hoy va a seguir siendo válido en dos años. El data drift no existe.
Y hay tres razones más para hacerlo igual:
- Es una skill listable. Saber leer Excel desde un framework de automation es algo que muchas ofertas piden explícitamente. No mostrarlo sería dejar fuera algo que suma en CV.
- Mantengo paralelismo con mi serie de Selenium. Mi
ClientesTests.javaya hace exactamente esto. Replicarlo en Playwright cierra el círculo de la migración. - Si más adelante voy a integrar API testing con REST Assured o con
requestde Playwright, este post deja claro por qué la API es mejor para volumen — lo demuestro haciéndolo "mal" primero.
Así que lo hago, pero con los ojos abiertos sobre cuándo aplica y cuándo no. Eso ya es más senior que automatizar sin pensar.
Estructura nueva del proyecto
Hasta ahora mi proyecto de Playwright tenía solo pages/, tests/ y fixtures/. Para este post necesitaba tres carpetas nuevas:
playwright-typescript-framework/
├── test-data/
│ └── clientes-data.xlsx ← copiado desde el repo de Selenium
├── types/
│ └── Cliente.ts ← interface tipada
├── utils/
│ └── excelReader.ts ← función para leer el .xlsx
├── pages/
│ └── ClientesPage.ts ← extendida con leerGrillaCompleta()
└── tests/
└── serenity-clientes-excel.spec.ts
Tres decisiones:
test-data/ en la raíz, no adentro de tests/. Si mañana sumo más fixtures (JSON, CSV, archivos para upload), todo vive en un solo lugar predecible. Mezclar data con código de tests se vuelve un lío rápido.
types/ para una sola interface. Esto es ventaja directa de TypeScript sobre Java: declarás el contrato una vez (interface Cliente) y lo reusás en el reader del Excel, en el page de la grilla y en el test. El compilador te garantiza que las tres fuentes hablan el mismo idioma. En Java tendría que crear una clase con getters y setters y mantenerla sincronizada a mano.
No creé data/ClientesTestData.ts como hice en Java. En TypeScript con Playwright no existe el equivalente a @DataProvider con clase dedicada — el patrón idiomático es importar el reader directamente en el spec. Forzar la estructura Java acá sería ceremonia innecesaria.
Por qué exceljs y no xlsx
Las dos librerías más usadas para leer Excel desde Node son xlsx (también conocida como SheetJS) y exceljs. Elegí exceljs por tres razones concretas:
- Mejor mantenida. xlsx arrastra issues de seguridad y tiene release lento. exceljs está activa y responde a issues.
- API async nativa. Encaja con el modelo async/await de Playwright sin envolturas.
- TypeScript sin instalar tipos aparte. xlsx requiere
@types/xlsx. exceljs viene tipado de fábrica.
Instalación:
npm install --save-dev exceljs
El --save-dev lo guarda en devDependencies, no en dependencies. Razón: exceljs se usa solo para tests, no es código de producción. Misma lógica por la que @playwright/test está en devDependencies.
Cuando lo instalé apareció una catarata de npm warn deprecated de paquetes internos como inflight, glob@7, rimraf@2. Todos transitivos — son dependencias de exceljs, no las uso yo directamente. found 0 vulnerabilities confirma que no hay nada explotable. Son avisos de "esto va a dejar de mantenerse en el futuro", no "está roto ahora".
Esto es algo que en Java con Maven se siente menos: cada dependencia que declarás es la que usás, punto. Node tiene árboles de dependencias más grandes y más ruidosos. No es bueno ni malo, es distinto.
La interface Cliente
Antes del reader, el contrato. types/Cliente.ts:
export interface Cliente {
id: string;
empresa: string;
contacto: string;
titulo: string;
region: string;
codigoPostal: string;
pais: string;
ciudad: string;
telefono: string;
fax: string;
representantes: string;
}
Once campos, todos string. En Java esto sería una clase con once getters y once setters. Acá son once líneas declarativas. El compilador me va a marcar en rojo cualquier lugar donde falte un campo o sobre uno.
El reader del Excel
utils/excelReader.ts:
import ExcelJS from 'exceljs';
import { Cliente } from '../types/Cliente';
/**
* Lee un archivo Excel con datos de clientes y devuelve un Map indexado por ID.
*
* El Excel debe tener la hoja "Clientes" con las columnas en este orden:
* A: ID, B: Empresa, C: Contacto, D: Titulo, E: Region,
* F: CodigoPostal, G: Pais, H: Ciudad, I: Telefono, J: Fax, K: Representantes
*
* @param rutaArchivo - Ruta al archivo .xlsx (relativa al cwd o absoluta)
* @returns Map<string, Cliente> donde la key es el ID del cliente
*/
export async function leerClientesDesdeExcel(
rutaArchivo: string
): Promise<Map<string, Cliente>> {
const workbook = new ExcelJS.Workbook();
await workbook.xlsx.readFile(rutaArchivo);
const hoja = workbook.getWorksheet('Clientes');
if (!hoja) {
throw new Error(`No se encontró la hoja "Clientes" en ${rutaArchivo}`);
}
const clientes = new Map<string, Cliente>();
// eachRow itera empezando en 1 (no en 0).
// includeEmpty: false salta filas completamente vacías.
hoja.eachRow({ includeEmpty: false }, (row, rowNumber) => {
// Salteamos la fila 1 (headers)
if (rowNumber === 1) return;
// row.getCell(N) — las columnas también empiezan en 1, no en 0.
// .text devuelve el valor como string (más seguro que .value, que puede ser
// number, Date, formula object, etc. dependiendo del tipo de celda).
const cliente: Cliente = {
id: row.getCell(1).text.trim(),
empresa: row.getCell(2).text.trim(),
contacto: row.getCell(3).text.trim(),
titulo: row.getCell(4).text.trim(),
region: row.getCell(5).text.trim(),
codigoPostal: row.getCell(6).text.trim(),
pais: row.getCell(7).text.trim(),
ciudad: row.getCell(8).text.trim(),
telefono: row.getCell(9).text.trim(),
fax: row.getCell(10).text.trim(),
representantes: row.getCell(11).text.trim(),
};
// Si la fila no tiene ID, la salteamos (fila basura)
if (!cliente.id) return;
clientes.set(cliente.id, cliente);
});
return clientes;
}Devuelve un Map<string, Cliente> indexado por ID — el mismo patrón que ya usaba en Java con Map<String, String[]>. Buscar por ID es O(1) y el orden físico del Excel no importa.
Las dos mordidas de exceljs
Las filas y columnas empiezan en 1, no en 0. getCell(1) es la columna A. Si venís de Apache POI en Java es lo mismo. Si venís de pensar en arrays JS, te confunde la primera vez. Es la primera mordida clásica.
.text en vez de .value. Cada celda tiene dos propiedades: value devuelve el dato en su tipo nativo (number, Date, formula object, etc.) y text devuelve siempre el string como lo verías en Excel. Para validar contra una grilla web (donde todo es texto), .text es lo que querés. Te ahorra conversiones manuales y bugs sutiles donde una celda numérica no compara con su versión renderizada.
Test rápido del reader
Antes de seguir, un debug minimal para confirmar que lee bien:
const ruta = path.join(__dirname, '..', 'test-data', 'clientes-data.xlsx');
const clientes = await leerClientesDesdeExcel(ruta);
console.log(`Total clientes leídos: ${clientes.size}`);
Resultado:
Total clientes leídos: 91
Primeros 3:
DRACD: Drachenblut Delikatessen - DE Germany
DUMON: Du monde entier - FR France
EASTCs: Eastern Connection - GB UK
91 clientes, perfecto. Pero anoten los primeros 3 — tres detalles importantes que vamos a usar después:
_ El orden refleja el orden físico del Excel, no alfabético. El Excel está desordenado.
_ El campo país viene con prefijo de dos letras: DE Germany, FR France, GB UK. Esto va a ser importante.
_ EASTCs tiene una s minúscula al final. Sospechoso. Los IDs del Northwind suelen ser de cinco letras mayúsculas.
El error que casi cometí: anticipar problemas que no existen
Cuando vi DE Germany, mi reflejo fue agregar una función para limpiar el prefijo:
function limpiarPrefijoPais(valorCelda: string): string {
const texto = valorCelda.trim();
const match = texto.match(/^[A-Z]{2}\s+(.+)$/);
return match ? match[1] : texto;
}
Lo agregué, lo testée, funcionó. DE Germany → Germany. Listo.
Y casi rompo todo.
Más adelante, cuando leí la grilla web por primera vez, descubrí que la grilla también muestra DE Germany, no Germany. La banderita es una imagen aparte; el código de país está en el DOM como texto. Ambos lados (Excel y grilla) tienen el mismo formato.
Si hubiese dejado el limpiarPrefijoPais, mi test habría fallado en los 91 países como falsa diferencia: Excel diciendo Germany y grilla diciendo DE Germany. Habría perdido tiempo investigando un problema que yo mismo me creé.
Lección concreta: no resuelvas problemas que no aparecieron todavía. Saqué la función. El reader vuelve a leer el país tal cual está en el Excel. Y la moraleja queda anotada para cualquiera que lea esto: la voz de "anticipo todo" es la voz que rompe las cosas. Build first, fix what breaks.
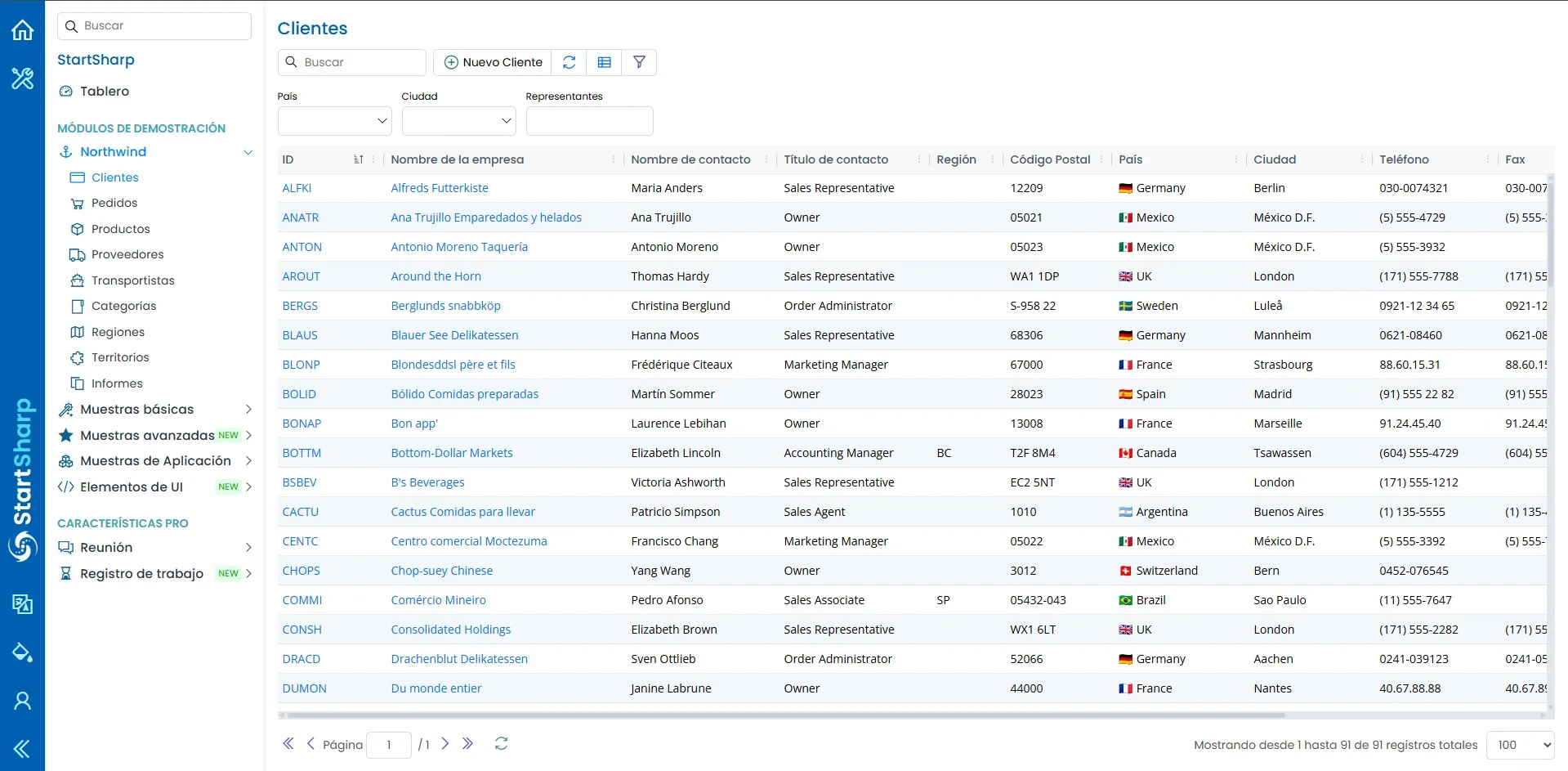
Leer la grilla: el problema de SlickGrid
La grilla de Serenity usa SlickGrid, un componente que virtualiza el DOM. Esto significa que aunque la grilla diga "Mostrando 1 hasta 91 de 91 registros", solo las filas visibles en el viewport están renderizadas en el HTML. Si scrolleás, las filas de arriba se desmontan del DOM y se montan las nuevas.
Si hago page.locator('div.slick-row').all() esperando los 91 registros, recibo solo los ~20 que están visibles en pantalla. Las otras 71 no existen en el DOM hasta que scrolleás.
En Selenium ya había resuelto esto con JavascriptExecutor para scrollear y leer en bloque. La estrategia es la misma en Playwright, pero la ejecución cambia bastante.
Primer intento: usar Locators de Playwright (y por qué falla)
Mi primera versión de leerGrillaCompleta usaba la API "linda" de Playwright: scrollear, hacer grillaFilas.all() para tomar las filas visibles, y para cada fila recorrer las celdas con locator('div.slick-cell.l0'), l1, l2, etc., leyendo innerText().
Lo corrí. Timeout a los 30 segundos.
Test timeout of 30000ms exceeded.
Error: locator.count: Test timeout
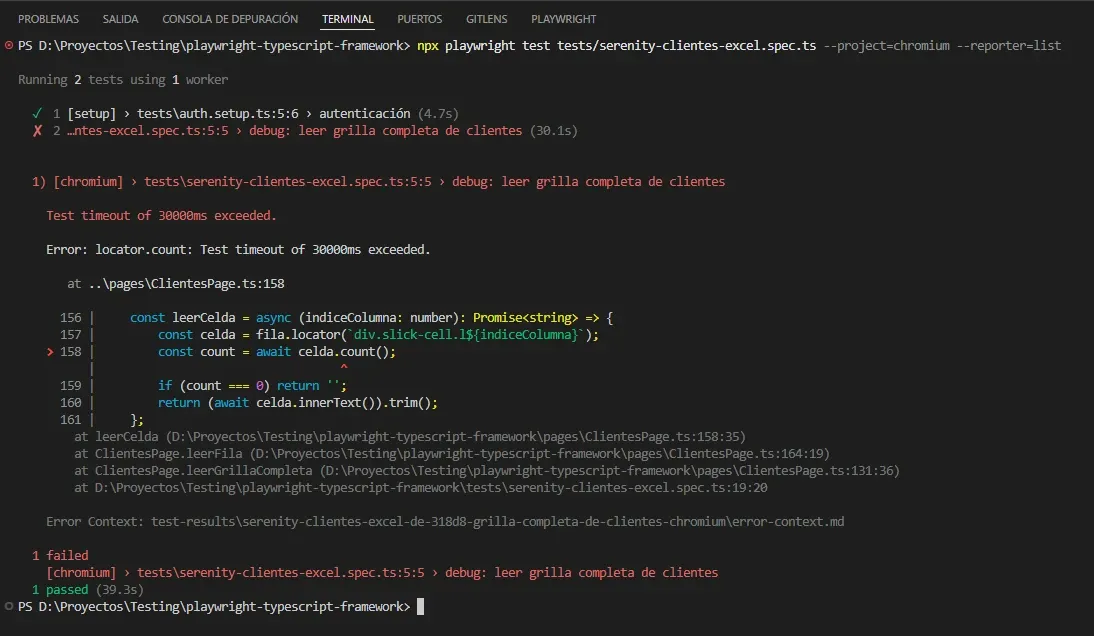
Me llevó un rato entender por qué. Dos razones, ambas importantes:
1. Los Locators de Playwright son lazy. Cuando hacés grillaFilas.all(), no recibís un array de elementos congelados — recibís un array de "consultas pendientes". Cada vez que usás un Locator, Playwright vuelve a buscar el elemento en el DOM. El problema con SlickGrid: entre que tomás las filas y empezás a leer las celdas, el DOM ya cambió. Las filas que habías "agarrado" están desmontadas. El Locator queda esperando a un elemento que nunca va a aparecer.
2. Es lentísimo aunque funcionara. Cada lectura de celda son dos viajes al browser (uno para count(), otro para innerText()). 11 columnas × 20 filas × varios scrolls = cientos de round-trips Node↔browser, cada uno costando algunos milisegundos. Suma rápido.
Segundo intento: bajar a page.evaluate
La solución correcta: hacer toda la lectura de las filas visibles en una sola llamada a page.evaluate() por cada posición de scroll. En lugar de iterar con Locators, ejecuto JavaScript directo en el browser que recorre el DOM completo y devuelve los datos como un array. Una sola ida y vuelta por scroll, sin staleness, mucho más rápido.
El método final, en pages/ClientesPage.ts:
async leerGrillaCompleta(): Promise<Map<string, Cliente>> {
await this.esperarGrillaCargada();
const clientes = new Map<string, Cliente>();
// Dimensiones del viewport
const dimensiones = await this.grillaViewport.evaluate((viewport) => ({
alturaTotal: viewport.scrollHeight,
alturaVisible: viewport.clientHeight,
}));
// Reset al tope
await this.grillaViewport.evaluate((vp) => { vp.scrollTop = 0; });
await this.page.waitForTimeout(300);
// Scroll de a medio viewport para solapar y no perder filas
const paso = Math.floor(dimensiones.alturaVisible / 2);
for (let pos = 0; pos <= dimensiones.alturaTotal; pos += paso) {
await this.grillaViewport.evaluate(
(vp, scrollPos) => { vp.scrollTop = scrollPos; },
pos
);
await this.page.waitForTimeout(200);
// UNA sola llamada al browser que extrae todas las filas visibles
const filasData = await this.page.evaluate(() => {
const filas = document.querySelectorAll('div.slick-row');
const resultado: string[][] = [];
for (const fila of filas) {
const valores: string[] = [];
for (let col = 0; col < 11; col++) {
const celda = fila.querySelector(`div.slick-cell.l${col}`);
valores.push(celda ? (celda.textContent ?? '').trim() : '');
}
resultado.push(valores);
}
return resultado;
});
// Procesamos en Node, sin tocar más el browser
for (const valores of filasData) {
const id = valores[0];
if (!id || clientes.has(id)) continue;
clientes.set(id, {
id: valores[0],
empresa: valores[1],
contacto: valores[2],
titulo: valores[3],
region: valores[4],
codigoPostal: valores[5],
pais: valores[6],
ciudad: valores[7],
telefono: valores[8],
fax: valores[9],
representantes: valores[10],
});
}
}
return clientes;
}
Tres puntos que vale la pena explicar:
1. page.evaluate corre en el browser, no en Node. La función arrow se serializa, se envía al browser, se ejecuta en el contexto del DOM real, y el resultado vuelve a Node como JSON. El parámetro viewport adentro del callback es el HTMLElement real, no un Locator. No podés usar variables de Node ahí adentro. Es el equivalente a executeScript de Selenium, pero tipado y formateado por el editor.
2. waitForTimeout(200) es justificado acá. En Playwright los waitForTimeout se consideran code smell y casi siempre hay que reemplazarlos por waits inteligentes. Pero acá es uno de los pocos casos donde es lo correcto: no estoy esperando que aparezca un elemento, estoy esperando que SlickGrid termine de renderizar las filas para la nueva posición de scroll. No hay un evento DOM ni un atributo que cambie y pueda esperar. 200ms es empírico — lo mínimo que funciona consistentemente.
3. El Map deduplica por ID automáticamente. Como solapo el scroll de a medio viewport, una misma fila puede aparecer en dos pasos seguidos. El clientes.has(id) evita reescribirla.
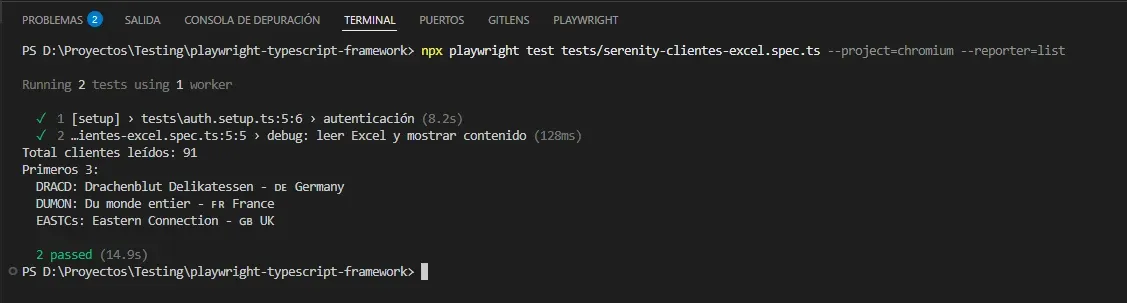
Corrida:
Total clientes leídos de la grilla: 91
Primeros 3:
ALFKI: Alfreds Futterkiste | DE Germany | Berlin
ANATR: Ana Trujillo Emparedados y helados | MX Mexico | México D.F.
ANTON: Antonio Moreno Taquería | MX Mexico | México D.F.
Últimos 3 IDs leídos:
WHITC, WILMK, WOLZA
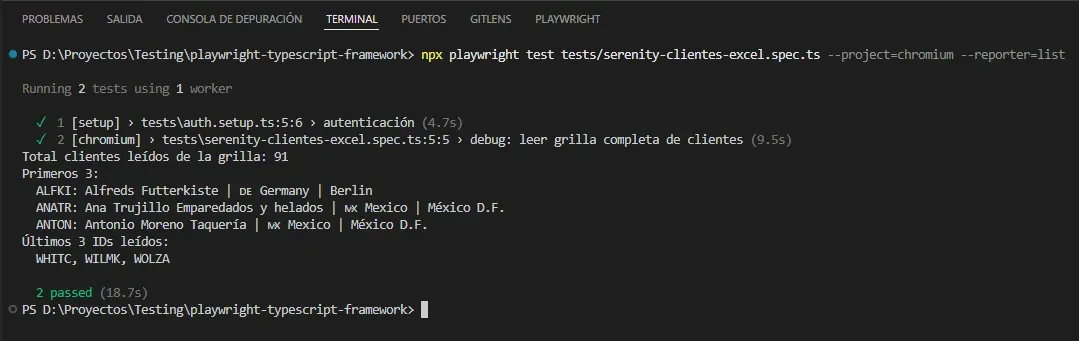
91 filas. La grilla por defecto está ordenada alfabéticamente por ID, ALFKI primero, WOLZA último. La lectura completa tarda ~9 segundos, razonable considerando que hace múltiples scrolls y lee 91 × 11 = 1001 celdas.
Bonus: cuando Chromium se cuelga con poca RAM
Antes de las dos corridas exitosas, las dos primeras me dieron errores raros:
GPU process launch failed: error_code=63
The GPU process has crashed 6 time(s)
Worker teardown timeout of 30000ms exceeded
Y después:
FATAL ERROR: Allocation failed - JavaScript heap out of memory
worker process exited unexpectedly (code=134)
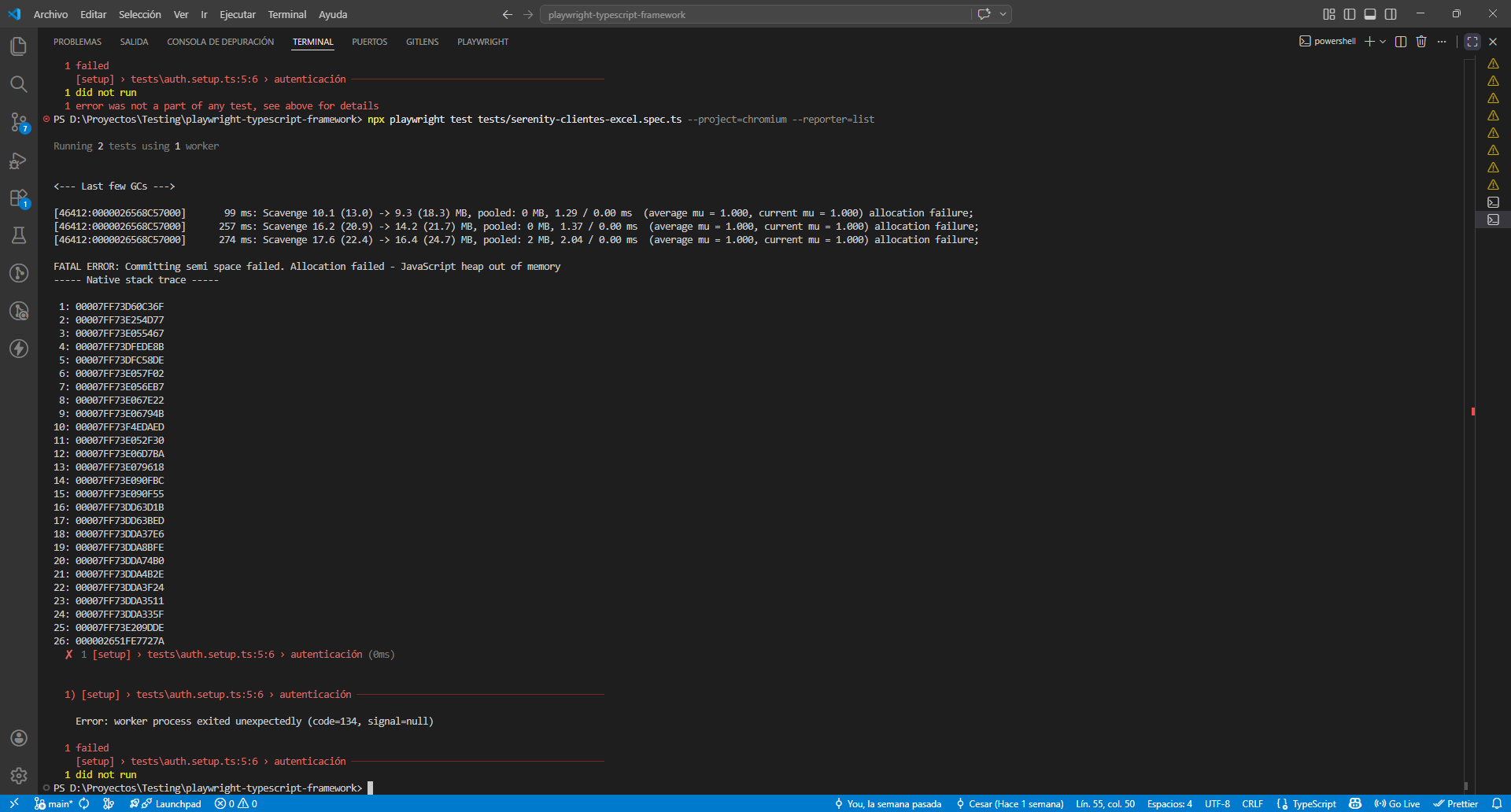
Esto no era un bug del test. Eran procesos zombies de Chromium de corridas anteriores que quedaron colgados consumiendo memoria, sumado a que tenía VS Code, IntelliJ y varios chromiums abiertos en una notebook con 8 GB de RAM.
Solución: cerrar VS Code, cerrar IntelliJ, abrir VS Code de nuevo, correr el test. Funcionó al primer intento.
Lo dejo anotado porque a cualquiera con un setup parecido le va a pasar tarde o temprano. No es culpa de Playwright — es la realidad de correr browsers reales en local con memoria justa.
El spec de comparación
Ya tengo las dos mitades funcionando: el reader del Excel y el reader de la grilla, ambos devolviendo Map<string, Cliente>. El test ahora es la parte fácil: iterar el Excel, buscar cada cliente en el Map de la grilla, comparar campo a campo.
tests/serenity-clientes-excel.spec.ts:
import { test, expect } from '@playwright/test';
import { ClientesPage } from '../pages/ClientesPage';
import { DashboardPage } from '../pages/DashboardPage';
import { leerClientesDesdeExcel } from '../utils/excelReader';
import path from 'path';
test('los 91 clientes de la grilla coinciden con el Excel', async ({ page }) => {
// 1. Leer Excel
const rutaExcel = path.join(__dirname, '..', 'test-data', 'clientes-data.xlsx');
const clientesExcel = await leerClientesDesdeExcel(rutaExcel);
// 2. Navegar a la grilla
const dashboard = new DashboardPage(page);
const clientesPage = new ClientesPage(page);
await page.goto('https://demo.serenity.is/');
await dashboard.verificarVisible();
await dashboard.irAClientes();
await clientesPage.verificarVisible();
// 3. Leer grilla
const clientesGrilla = await clientesPage.leerGrillaCompleta();
// 4. Validar conteo
expect.soft(
clientesGrilla.size,
'Cantidad total de clientes (grilla vs Excel)'
).toBe(clientesExcel.size);
// 5. Validar campo a campo
for (const [id, esperado] of clientesExcel) {
const real = clientesGrilla.get(id);
if (!real) {
expect.soft(real, `Cliente ${id} debería existir en la grilla`).toBeDefined();
continue;
}
expect.soft(real.empresa, `${id} - Empresa`).toBe(esperado.empresa);
expect.soft(real.contacto, `${id} - Contacto`).toBe(esperado.contacto);
expect.soft(real.titulo, `${id} - Título`).toBe(esperado.titulo);
expect.soft(real.region, `${id} - Región`).toBe(esperado.region);
expect.soft(real.codigoPostal, `${id} - Código Postal`).toBe(esperado.codigoPostal);
expect.soft(real.pais, `${id} - País`).toBe(esperado.pais);
expect.soft(real.ciudad, `${id} - Ciudad`).toBe(esperado.ciudad);
expect.soft(real.telefono, `${id} - Teléfono`).toBe(esperado.telefono);
expect.soft(real.fax, `${id} - Fax`).toBe(esperado.fax);
expect.soft(real.representantes, `${id} - Representantes`).toBe(esperado.representantes);
}
});
Tres decisiones del código:
1. Un solo test, no 91 tests data-driven. Podría haber usado el patrón for...of con test() adentro como en el Post 8, generando un test por cada cliente. No tiene sentido acá: 91 tests significan 91 setups, 91 navegaciones, 91 lecturas con scroll. Tardaría minutos. Con un solo test, leo la grilla una sola vez y comparo contra el Map ya cargado. Además, 91 tests verdes con 4 rojos en el reporte es ruido. Un solo test con 4 fallas claras es más legible.
2. expect.soft en lugar de expect. Las soft assertions acumulan fallas en lugar de cortar al primer error. Al final del test, si hubo al menos una falla, el test falla — pero entre medio ejecuta todo. Para validación de volumen, esta es la única estrategia útil: quiero ver todas las diferencias en una sola corrida, no ir descubriendo errores de a uno.
Esto contradice algo que dije en el post (Data-driven testing en Playwright): "soft assertions no deberían ser globales". Y sigue siendo cierto en aquel contexto. Acá el contexto es distinto — un test único validando 910 cosas. Misma herramienta, distinto criterio según contexto. Eso es lo que termina siendo "senior": no es saber la respuesta correcta, es saber qué pregunta hacerse antes.
3. Iterar el Excel, no la grilla. El Excel es la fuente de verdad — define qué clientes deberían estar y con qué datos. Si iterara la grilla, no detectaría clientes que están en el Excel pero no en la grilla (registros faltantes). Iterando el Excel sí los detecto, con el if (!real). Cuando comparás dos fuentes, siempre iterás la "esperada" contra la "real", no al revés.
4. El segundo argumento de expect.soft. Ese mensaje custom (${id} - Empresa) es lo más importante del test. Sin él, cuando una assertion falle, el reporte dice algo como "Expected: 'X', Received: 'Y'" sin contexto. Con él, vas a ver "FOLKO - País: Expected 'Sweden', Received 'Norway'" y sabés instantáneamente cuál cliente y cuál campo. En un test que hace 910 comparaciones, esto es la diferencia entre debuggear 5 minutos o 2 horas.
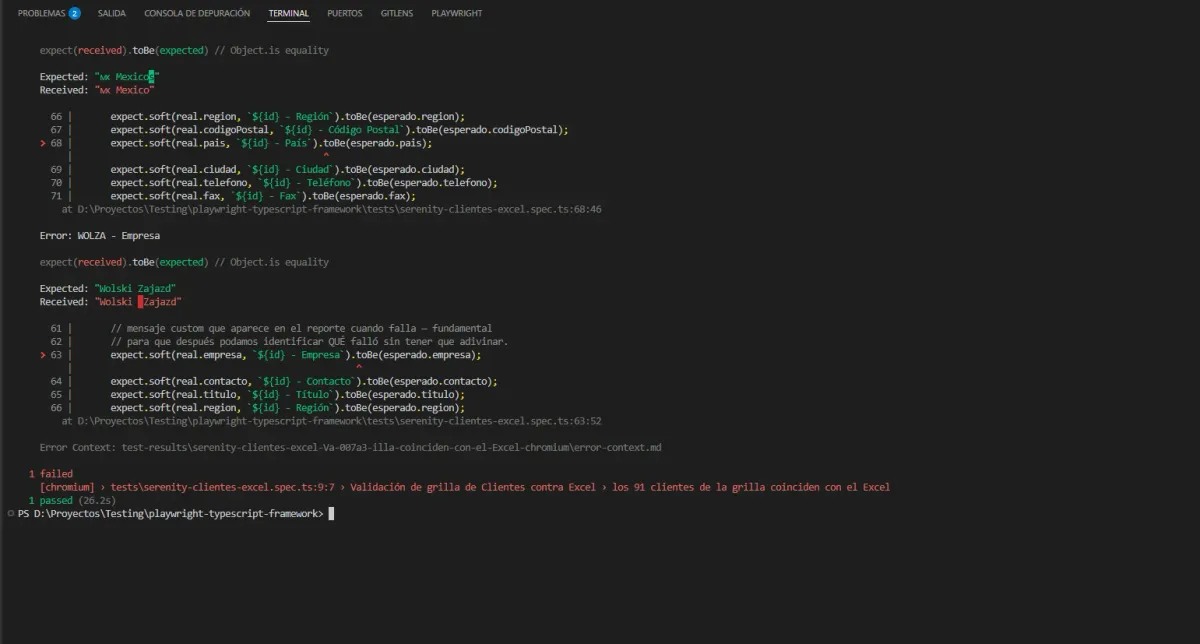
Los errores que aparecieron
Corrí el test esperando que fallara — el Excel que uso es el mismo que tenía en mi serie de Selenium, y le había metido 3 errores intencionales para mostrar cómo se reportaban en Allure. Esperaba ver esos 3.
Aparecieron 4.
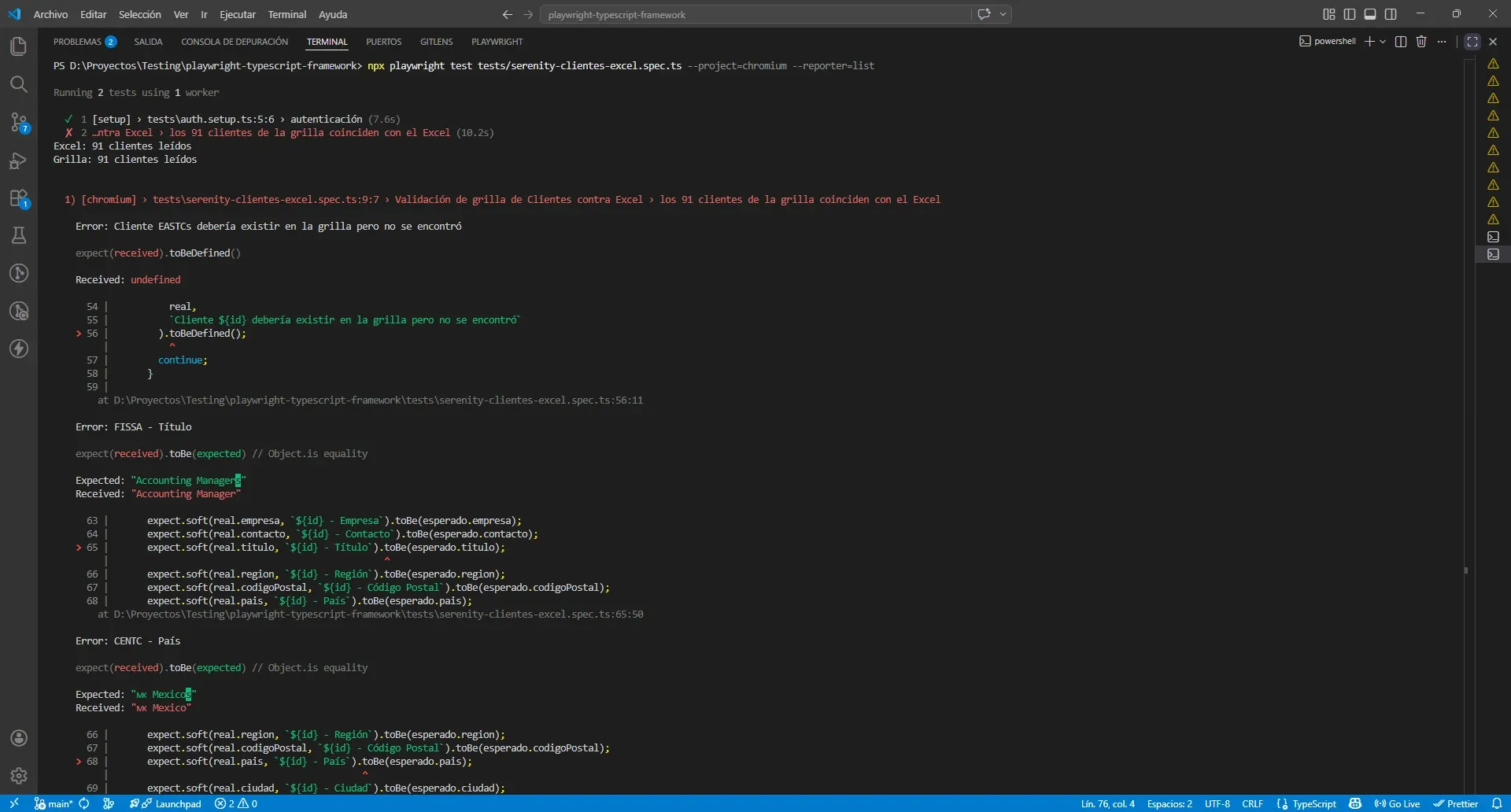
Error 1: Cliente EASTCs debería existir en la grilla pero no se encontró
El Excel tiene el ID escrito como EASTCs (con s minúscula al final). En la grilla está como EASTC. El Map no encontró match porque las keys son distintas: "EASTCs" !== "EASTC".
Este es un typo del Excel, no un bug de la app. Caso clásico: la fuente de verdad miente.
Error 2: FISSA - Título
Expected: "Accounting Managers" ← Excel
Received: "Accounting Manager" ← Grilla
Excel tiene "Managers" en plural, grilla "Manager" en singular. Otro typo intencional.
Error 3: CENTC - País
Expected: "MX Mexicos" ← Excel
Received: "MX Mexico" ← Grilla
"Mexicos" en el Excel, "Mexico" en la grilla. Tercer typo intencional.
Hasta acá, todo lo que esperaba. Tres errores que yo mismo había metido en el dataset de Selenium para demostrar cómo se reportan las fallas. Pero apareció uno más.
El cuarto error: WOLZA — el bug que Selenium nunca había encontrado
Expected: "Wolski Zajazd" ← Grilla
Received: "Wolski Zajazd" ← Excel (doble espacio)
El Excel tiene Wolski Zajazd con dos espacios entre las palabras. La grilla tiene un solo espacio. Yo no introduje este error. El Excel ya estaba así. Yo lo había usado durante toda mi serie de Selenium con ClientesTests.java y nunca había notado nada.
Mi suite de Selenium pasaba en verde (excepto los 3 errores intencionales), y este bug estaba sentado ahí, escondido entre dos espacios. Imposible verlo a simple vista en una hoja de cálculo. Imposible verlo en una grilla web donde el navegador colapsa los espacios al renderizar.
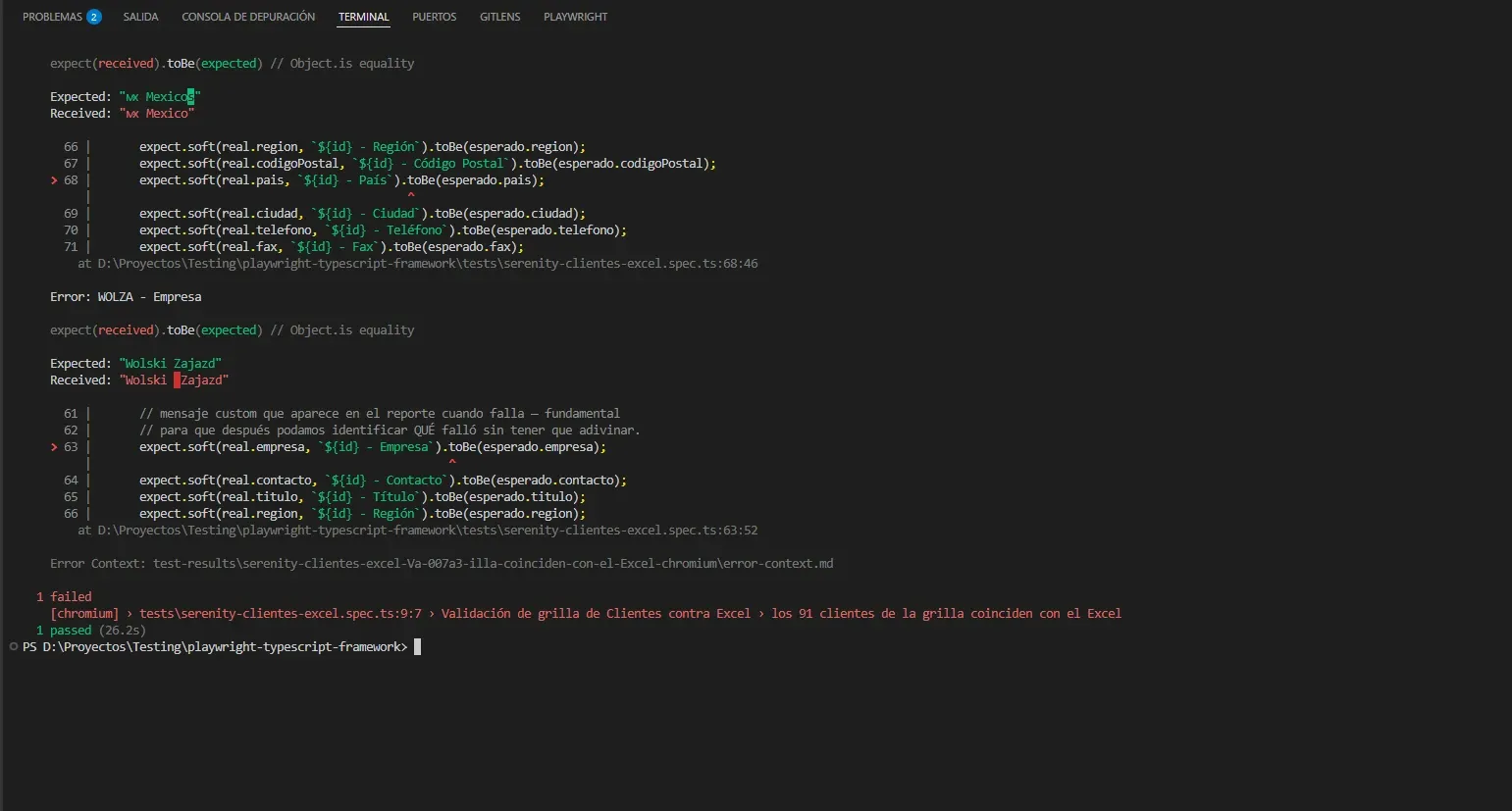
Lo que más me llama la atención es cómo lo muestra Playwright: en la línea Received resalta exactamente el carácter de más en rojo. Si no fuera por ese resaltado, ver el doble espacio entre Wolski y Zajazd sería casi imposible — son dos espacios pegados, no se nota.
¿Por qué Selenium con TestNG no lo detectó? Honestamente, no lo sé. Mi Assert.assertEquals debería haberlo agarrado igual. Puede ser que tuviera algún .trim() de más en algún lado, o que el assertion message no fuera lo suficientemente granular como para que yo lo viera. Voy a tener que volver a la suite de Java a chequear. Pero el hecho concreto es: durante toda la serie de Selenium, este bug estaba ahí. Playwright lo encontró la primera vez que corrí el test.
Esto es lo que más me hace pensar de todo el ejercicio. Más que las decisiones de arquitectura, más que el pattern de leer la grilla, más que la elección de exceljs. La automatización de QA no se trata solo de "automatizar lo que ya hago manual". Se trata de detectar lo que el ojo humano se pierde. Un doble espacio en una celda de Excel no se ve. Una assertion automatizada con un buen reporte sí.
Y para ser totalmente honesto: este post iba a ser sobre validar 91 clientes con Excel. Terminó siendo sobre encontrar un bug que llevaba meses escondido en mi propio dataset.
Comparación rápida: Selenium + TestNG vs Playwright + TS
| Aspecto | Selenium + Java | Playwright + TS |
|---|---|---|
| Lectura de Excel | Apache POI (sync) | exceljs (async) |
| Tipado de los datos | Clase con getters/setters | Interface (11 líneas) |
| Lectura masiva del DOM | JavascriptExecutor.executeScript con string de JS |
page.evaluate con función TS tipada |
| Soft assertions | SoftAssert de TestNG |
expect.soft nativo |
| Mensaje custom en assertion | Tercer argumento de assertEquals |
Segundo argumento de expect.soft |
| Reporte de diferencias | Texto plano, requiere leer con cuidado | Diff visual con resaltado de chars |
Las dos suites hacen lo mismo. Pero la experiencia de leer un fallo es bastante distinta. El resaltado visual del doble espacio en WOLZA no es solo una mejora estética — es lo que hace que un bug invisible pase a ser obvio.
Próximo post
Este post cubrió la validación de datos de la grilla. La grilla tiene mucho más para testear: filtros (País, Ciudad, Representantes), ordenamiento por columna, búsqueda por texto, paginación. Todas esas son interacciones de UI que no necesitan Excel — son tests más cortos, más rápidos, más estables, y cubren las funcionalidades reales que un usuario usa todos los días.
En el próximo post: testing de grilla — filtros, ordenamiento y búsqueda en SlickGrid con Playwright. Sin Excel, sin scroll programático, sin volumen. Solo interacciones reales.
—
🔗 Todo el código de esta serie está en: github.com/cesarbeassuarez/playwright-typescript-framework